require(readxl)
pokemon <- read_excel(path = "Pokemon.xlsx", sheet = "Pokemon")¿Cómo filtrar datos en Excel y R? (Parte 1: filtros básicos)
Explora nuestros posts y nuestros cursos
En el análisis de datos, es importante tener datos limpios y sin errores. Los datos duplicados, los valores faltantes y los datos extremos pueden causar problemas, como sesgos en los resultados del análisis. Por eso, es importante saber cómo filtrar los datos para eliminar estos problemas.
Acerca de la información
Para este artículo, utilizaremos como ejemplo el archivo Pokemon.xlsx en donde contamos con un listado de los diferentes pokemones con información sobre sus niveles de ataque, defensa, entre otros. Para cargar nuestra tabla, usaremos las herramientas del paquete readxl (puedes revisar los detalles en nuestro artículo ¿Cómo cargar (leer) una tabla de Excel en R?).
En este artículo, mostraremos la manera de utilizar las herramientas disponibles en R base y utilizando funciones del paquete dplyr a partir de 10 ejercicios.
Ejercicio 1
Premisa: Aquellos considerados Legendarios, es decir, en donde el valor de la columna Legendary sea TRUE.
En Excel
El método por excelencia para ordenar datos es seleccionando las celdas de las cabeceras y dando click al botón Filtro en la pestaña Datos.
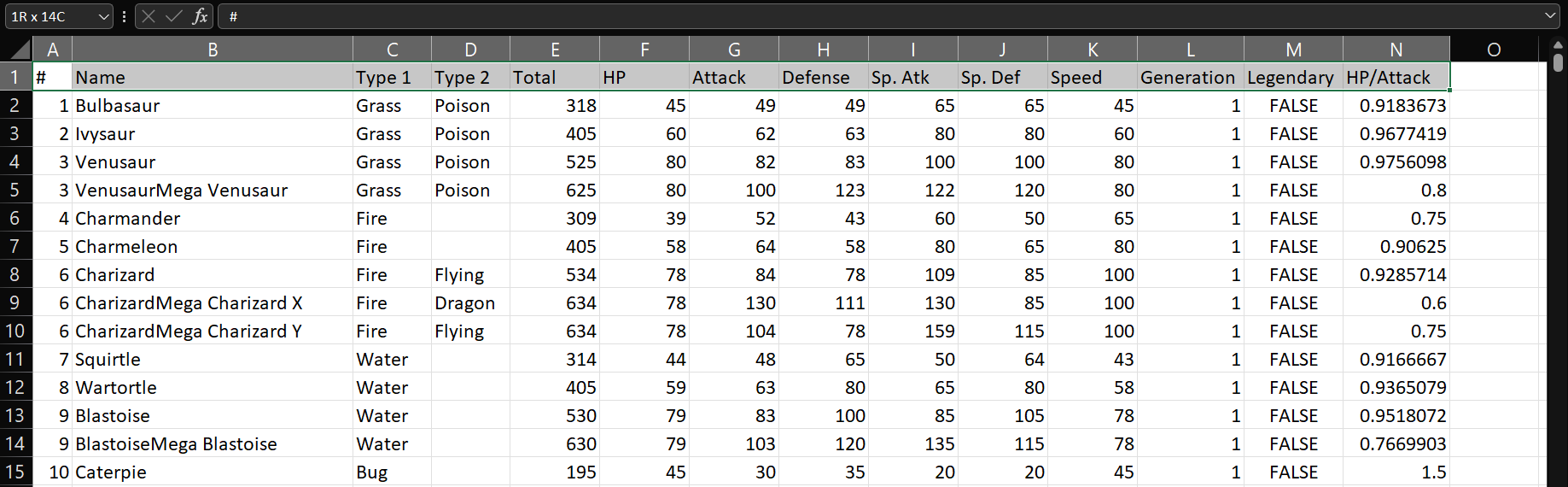
Para el primer ejemplo, iremos a la flecha disponible en la variable Legendary y veremos que se abre una ventana en donde podremos seleccionar el valor de interés, luego daremos click a OK.
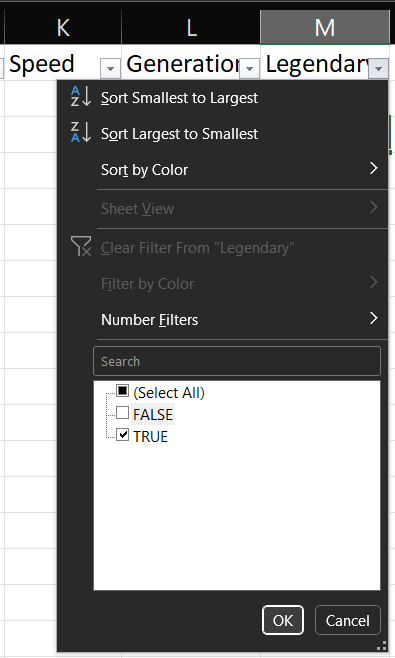
Veremos en la tabla resultante que Excel nos indica las filas en donde se cumple la condición (resaltadas con un ligero color turquesa). Así mismo, en la parte inferior izquierda, nos muestra la cantidad de filas que tiene nuestro subset respecto a la tabla original: 65 de 800.
En R (funciones de paquete base)
Para filtrar datos en R base, echaremos mano muchísimo del operador de indexación: los corchetes ([ ]). Particularmente, debido a que una tabla es un objeto de dos dimensiones (filas y columnas), dividiremos el espacio dentro de nuestro operador corchete en dos utilizando una coma del siguiente modo: [ , ]. El espacio entre el corchete de apertura y la coma contendrá los comandos para trabajar con las filas, mientras que el espacio entre la coma y el corchete de cierre servirá para trabajar con las columnas.
Entonces, para este primer ejercicio, colocaremos un comando con el que le indicaremos que necesitamos solo las filas en donde Legendary sea TRUE, del siguiente modo:
pokemon[pokemon$Legendary == TRUE,]# A tibble: 65 × 13
`#` Name `Type 1` `Type 2` Total HP Attack Defense `Sp. Atk` `Sp. Def`
<dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 144 Artic… Ice Flying 580 90 85 100 95 125
2 145 Zapdos Electric Flying 580 90 90 85 125 90
3 146 Moltr… Fire Flying 580 90 100 90 125 85
4 150 Mewtwo Psychic <NA> 680 106 110 90 154 90
5 150 Mewtw… Psychic Fighting 780 106 190 100 154 100
6 150 Mewtw… Psychic <NA> 780 106 150 70 194 120
7 243 Raikou Electric <NA> 580 90 85 75 115 100
8 244 Entei Fire <NA> 580 115 115 85 90 75
9 245 Suicu… Water <NA> 580 100 75 115 90 115
10 249 Lugia Psychic Flying 680 106 90 130 90 154
# ℹ 55 more rows
# ℹ 3 more variables: Speed <dbl>, Generation <dbl>, Legendary <lgl>
¿Por qué
== y no solo =?
En R, el comando = está reservado para asignación de objetos (ya sea dentro de un script o como argumentos en una función). Para labores de comparación, el comando correspondiente es ==, el cual resultará en un valor (o valores) de clase logical (es decir, TRUE o FALSE).
# ¿15 es igual a 20?
15 == 20[1] FALSEPodemos ver que la tabla resultado es la misma que con lo obtenido en Excel. Hay que tener que el método print en consola de nuestra tabla hará algunas abreviaciones, pero no hay de qué preocuparse ya que la información se mantiene intacta. Si queremos visualizar la tabla completa, podemos utilizar la función View de la siguiente forma:
View(pokemon[pokemon$Legendary == TRUE,])Esto abrirá una sub-ventana en donde podremos observar la tabla completa “a modo de Excel”.
En R (funciones de paquete dplyr)
Con dplyr, existen varias funciones para el manejo y filtrado de datos. Una de las más importantes es filter.
require(dplyr)
pokemon |>
filter(Legendary == TRUE)# A tibble: 65 × 13
`#` Name `Type 1` `Type 2` Total HP Attack Defense `Sp. Atk` `Sp. Def`
<dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 144 Artic… Ice Flying 580 90 85 100 95 125
2 145 Zapdos Electric Flying 580 90 90 85 125 90
3 146 Moltr… Fire Flying 580 90 100 90 125 85
4 150 Mewtwo Psychic <NA> 680 106 110 90 154 90
5 150 Mewtw… Psychic Fighting 780 106 190 100 154 100
6 150 Mewtw… Psychic <NA> 780 106 150 70 194 120
7 243 Raikou Electric <NA> 580 90 85 75 115 100
8 244 Entei Fire <NA> 580 115 115 85 90 75
9 245 Suicu… Water <NA> 580 100 75 115 90 115
10 249 Lugia Psychic Flying 680 106 90 130 90 154
# ℹ 55 more rows
# ℹ 3 more variables: Speed <dbl>, Generation <dbl>, Legendary <lgl>De nuevo, obtenemos el mismo resultado que con los métodos anteriores.
¿Qué significan los comandos
|> y %>%?
Dentro de nuestro artículo ¿Cómo eliminar filas con datos duplicados?, puedes revisar la nota referida a este punto titulada: ¿Qué significan los comandos |> y %>%?
Ejercicio 2
Premisa: Aquellos de tipo Planta y Dragón, es decir, en donde Type 1 tenga los valores de Grass o Dragon.
En Excel
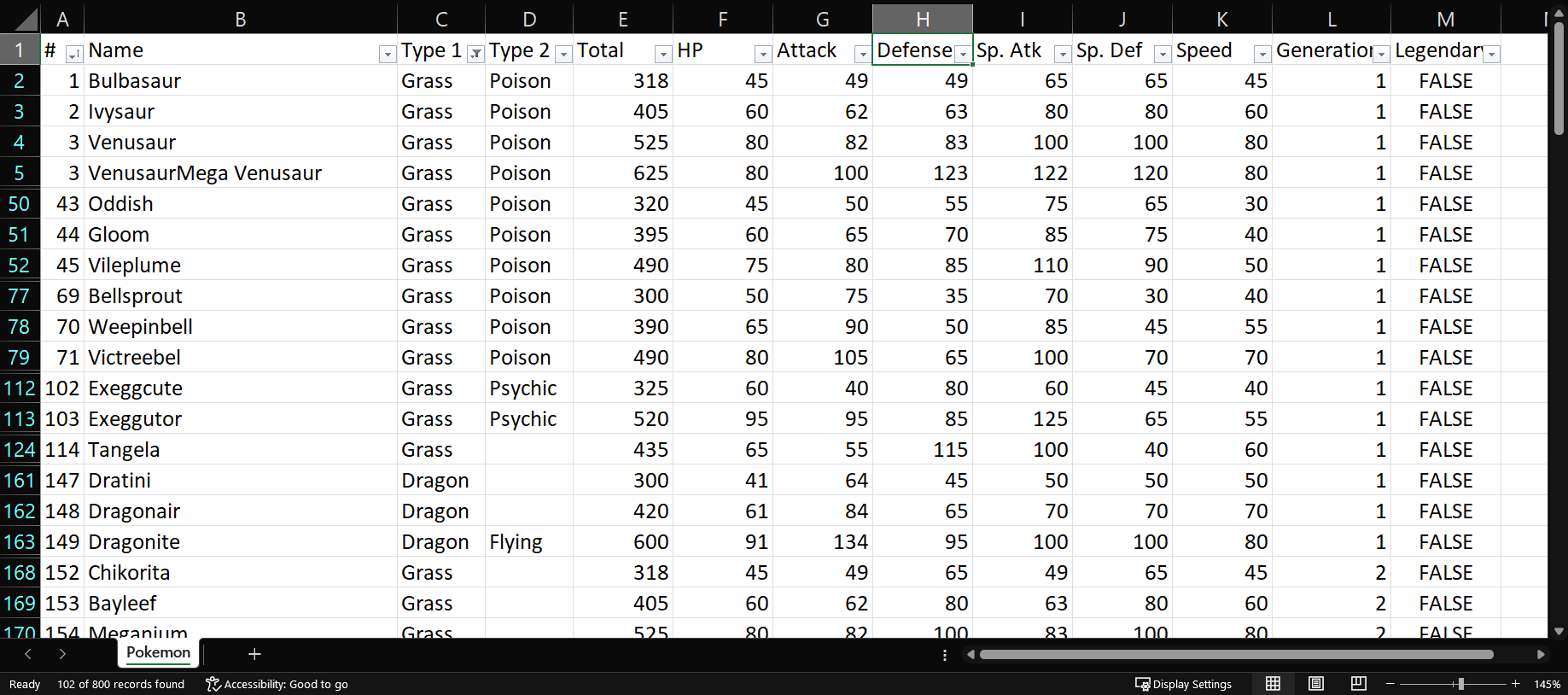
De forma similar al ejercicio anterior, iremos a la flecha de la variable Type 1 y seleccionaremos las casillas Grass y Dragon.
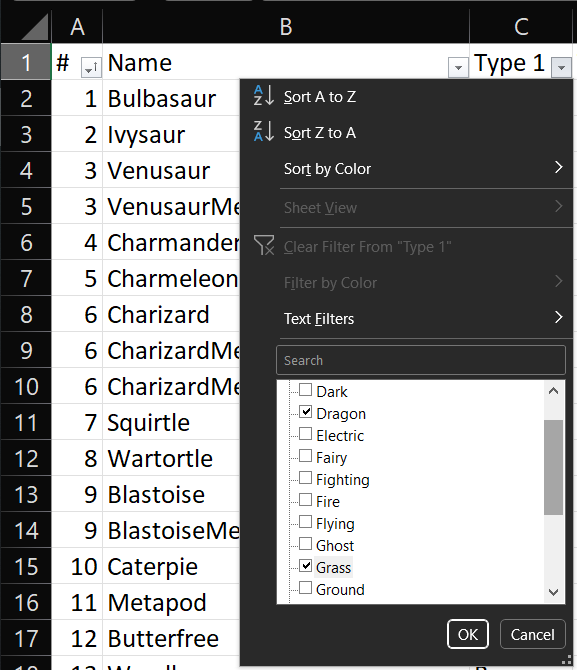
Tenemos como resultado, una tabla de 102 filas.
En R
Existen varias maneras de realizar esto, utilizando en todas ellas el espacio para indexación de filas nuestro operador [ , ].
# Opción 1
pokemon[pokemon$`Type 1` == "Grass" | `Type 1` == "Dragon",]
# Opción 2
pokemon[is.element(el = pokemon$`Type 1`, set = c("Grass", "Dragon")),]
# Opción 3
pokemon[pokemon$`Type 1` %in% c("Grass", "Dragon"),]# A tibble: 102 × 13
`#` Name `Type 1` `Type 2` Total HP Attack Defense `Sp. Atk` `Sp. Def`
<dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 1 Bulba… Grass Poison 318 45 49 49 65 65
2 2 Ivysa… Grass Poison 405 60 62 63 80 80
3 3 Venus… Grass Poison 525 80 82 83 100 100
4 3 Venus… Grass Poison 625 80 100 123 122 120
5 43 Oddish Grass Poison 320 45 50 55 75 65
6 44 Gloom Grass Poison 395 60 65 70 85 75
7 45 Vilep… Grass Poison 490 75 80 85 110 90
8 69 Bells… Grass Poison 300 50 75 35 70 30
9 70 Weepi… Grass Poison 390 65 90 50 85 45
10 71 Victr… Grass Poison 490 80 105 65 100 70
# ℹ 92 more rows
# ℹ 3 more variables: Speed <dbl>, Generation <dbl>, Legendary <lgl>
¿Qué hace la función
is.element y qué es el operador %in%?
La función is.element compara dos vectores (definidos en sus argumentos el y set). Lo que hará será devolver un vector de la misma longitud que el vector dado en el y de clase logical (i.e. con valores TRUE y FALSE) en será TRUE solo si un elemento de el se encuentra listado en el vector set. O dicho de otro modo, solo devolverá FALSE en aquellas posiciones en donde los elementos de el NO se encuentren en set.
Por otro lado, el operador %in% no es más que un modo abreviado de ejecutar is.element. Es decir, is.element(el, set) equivale a el %in% set.
is.element(el = "March", set = month.name)[1] TRUE"March" %in% month.name[1] TRUEis.element(el = "Monday", set = month.name)[1] FALSE"Monday" %in% month.name[1] FALSEEn R (funciones de paquete dplyr)
Utilizaremos nuevamente la función filter:
# Opción 1
pokemon |>
filter(`Type 1` == "Grass" | `Type 2` == "Dragon")
# Opción 2
pokemon |>
filter(is.element(el = `Type 1`, set = c("Grass", "Dragon")))
# Opción 3
pokemon |>
filter(`Type 1` %in% c("Grass", "Dragon"))# A tibble: 102 × 13
`#` Name `Type 1` `Type 2` Total HP Attack Defense `Sp. Atk` `Sp. Def`
<dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 1 Bulba… Grass Poison 318 45 49 49 65 65
2 2 Ivysa… Grass Poison 405 60 62 63 80 80
3 3 Venus… Grass Poison 525 80 82 83 100 100
4 3 Venus… Grass Poison 625 80 100 123 122 120
5 43 Oddish Grass Poison 320 45 50 55 75 65
6 44 Gloom Grass Poison 395 60 65 70 85 75
7 45 Vilep… Grass Poison 490 75 80 85 110 90
8 69 Bells… Grass Poison 300 50 75 35 70 30
9 70 Weepi… Grass Poison 390 65 90 50 85 45
10 71 Victr… Grass Poison 490 80 105 65 100 70
# ℹ 92 more rows
# ℹ 3 more variables: Speed <dbl>, Generation <dbl>, Legendary <lgl>Como podemos observar, la lógica de lo que va dentro de filter es la misma que lo usado con el paquete base, solo que dentro de filter ya no es necesario nombrar el objeto con la tabla original.
Ejercicio 3
Premisa: Aquellos con solo un tipo. Es decir, en donde Type 2 sea vacío o NA.
En Excel
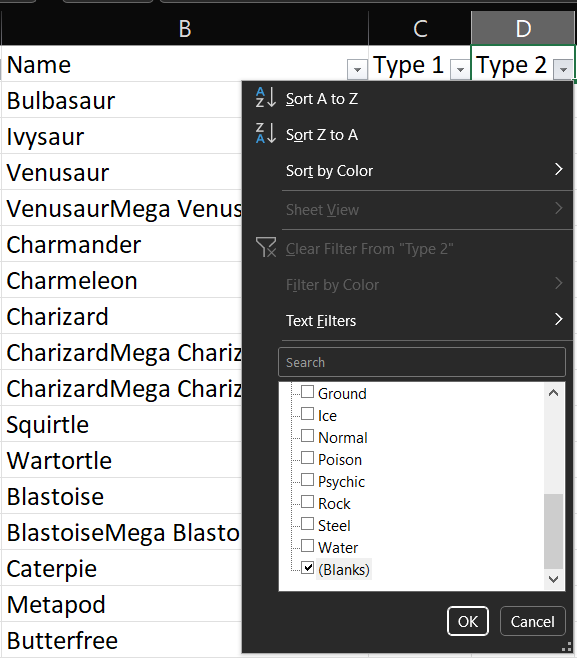
De forma similar, podemos ir a la columna Type 2 y seleccionar la casilla con los espacios catalogados (En blanco) o (Blanks).
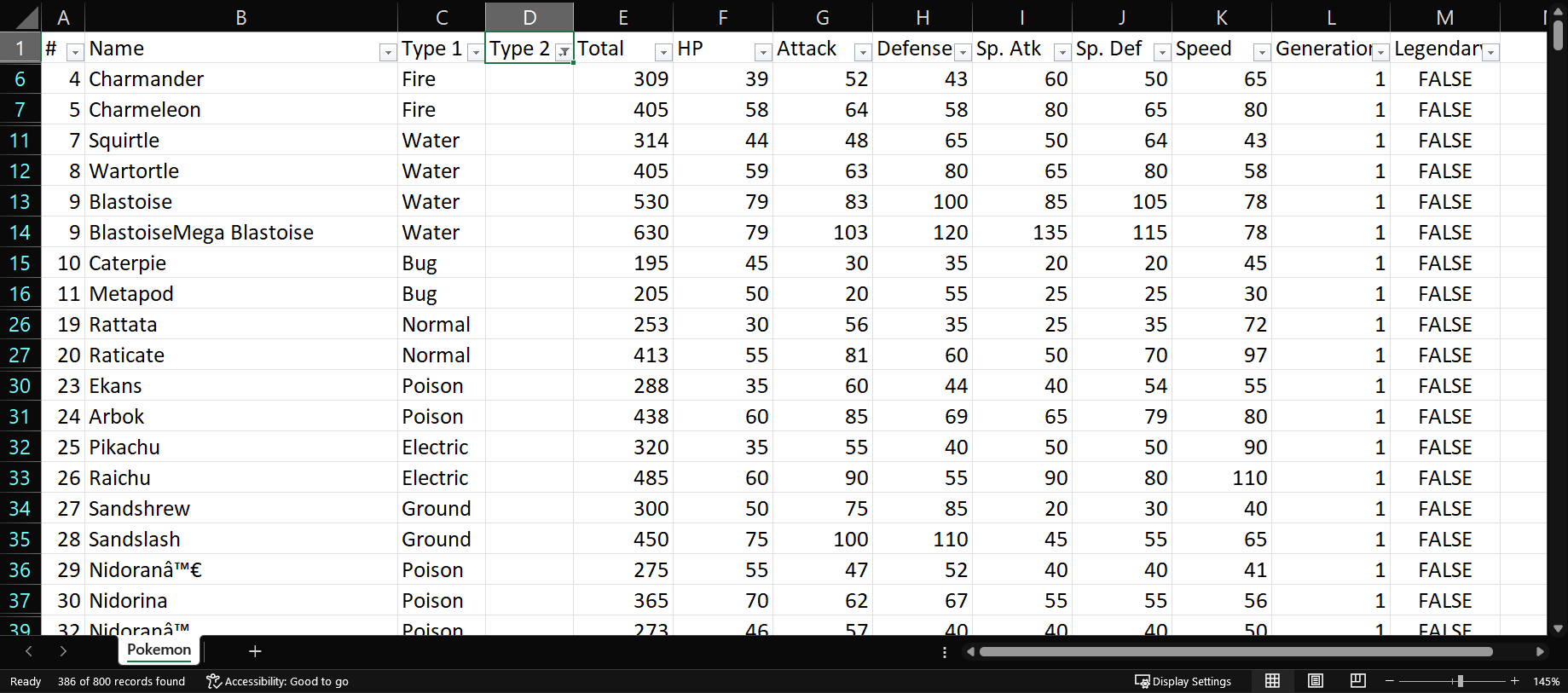
El resultado, una tabla con 386 filas que cumplen esa condición.
En R
Para evaluar qué posiciones de un vector son vacíos (o también conocidos como NA en entorno R), haremos uso de la función is.na:
pokemon[is.na(pokemon$`Type 2`),]# A tibble: 386 × 13
`#` Name `Type 1` `Type 2` Total HP Attack Defense `Sp. Atk` `Sp. Def`
<dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 4 Charm… Fire <NA> 309 39 52 43 60 50
2 5 Charm… Fire <NA> 405 58 64 58 80 65
3 7 Squir… Water <NA> 314 44 48 65 50 64
4 8 Warto… Water <NA> 405 59 63 80 65 80
5 9 Blast… Water <NA> 530 79 83 100 85 105
6 9 Blast… Water <NA> 630 79 103 120 135 115
7 10 Cater… Bug <NA> 195 45 30 35 20 20
8 11 Metap… Bug <NA> 205 50 20 55 25 25
9 19 Ratta… Normal <NA> 253 30 56 35 25 35
10 20 Ratic… Normal <NA> 413 55 81 60 50 70
# ℹ 376 more rows
# ℹ 3 more variables: Speed <dbl>, Generation <dbl>, Legendary <lgl>En R (funciones de paquete dplyr)
Utilizando la misma lógica dentro de filter:
pokemon |>
filter(is.na(`Type 2`))# A tibble: 386 × 13
`#` Name `Type 1` `Type 2` Total HP Attack Defense `Sp. Atk` `Sp. Def`
<dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 4 Charm… Fire <NA> 309 39 52 43 60 50
2 5 Charm… Fire <NA> 405 58 64 58 80 65
3 7 Squir… Water <NA> 314 44 48 65 50 64
4 8 Warto… Water <NA> 405 59 63 80 65 80
5 9 Blast… Water <NA> 530 79 83 100 85 105
6 9 Blast… Water <NA> 630 79 103 120 135 115
7 10 Cater… Bug <NA> 195 45 30 35 20 20
8 11 Metap… Bug <NA> 205 50 20 55 25 25
9 19 Ratta… Normal <NA> 253 30 56 35 25 35
10 20 Ratic… Normal <NA> 413 55 81 60 50 70
# ℹ 376 more rows
# ℹ 3 more variables: Speed <dbl>, Generation <dbl>, Legendary <lgl>Ejercicio 4
Premisa: Aquellos en donde su nivel de vida (variable HP) sea mayor a 100.
En Excel
Para este tipo de filtros, dentro de la ventana desplegable, se debe elegir la opción de Filtro de números y luego elegir la opción que se ajuste al criterio buscado. Para nuestro ejemplo, seleccionaremos la opción Mayor que (Greater than).
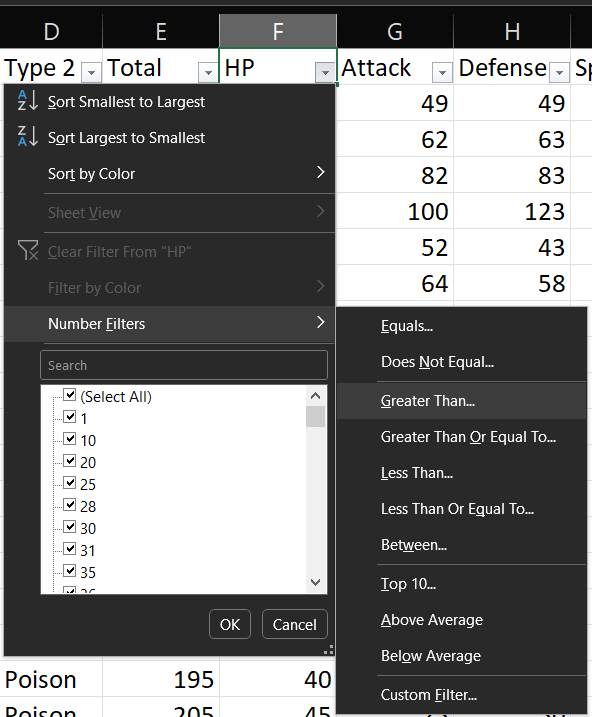
A continuación, se abrirá una ventana en donde colocaremos el valor de referencia solicitado (100) y luego click en Aceptar.
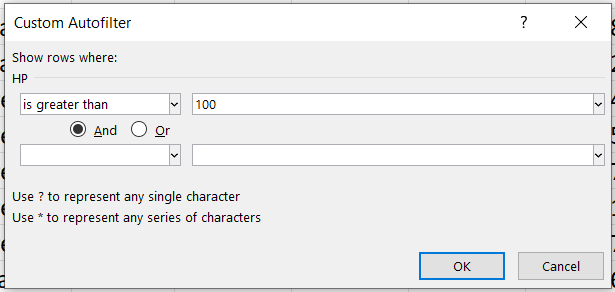
Nuestra tabla resultante tiene 67 filas.

En R
Bastará con usar apropiadamente el comando “mayor que” (>):
pokemon[pokemon$HP > 100,]# A tibble: 67 × 13
`#` Name `Type 1` `Type 2` Total HP Attack Defense `Sp. Atk` `Sp. Def`
<dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 39 Jiggl… Normal Fairy 270 115 45 20 45 25
2 40 Wiggl… Normal Fairy 435 140 70 45 85 50
3 89 Muk Poison <NA> 500 105 105 75 65 100
4 112 Rhydon Ground Rock 485 105 130 120 45 45
5 113 Chans… Normal <NA> 450 250 5 5 35 105
6 115 Kanga… Normal <NA> 490 105 95 80 40 80
7 115 Kanga… Normal <NA> 590 105 125 100 60 100
8 131 Lapras Water Ice 535 130 85 80 85 95
9 134 Vapor… Water <NA> 525 130 65 60 110 95
10 143 Snorl… Normal <NA> 540 160 110 65 65 110
# ℹ 57 more rows
# ℹ 3 more variables: Speed <dbl>, Generation <dbl>, Legendary <lgl>En R (funciones de paquete dplyr)
De forma similar dentro de filter:
pokemon |>
filter(HP > 100)# A tibble: 67 × 13
`#` Name `Type 1` `Type 2` Total HP Attack Defense `Sp. Atk` `Sp. Def`
<dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 39 Jiggl… Normal Fairy 270 115 45 20 45 25
2 40 Wiggl… Normal Fairy 435 140 70 45 85 50
3 89 Muk Poison <NA> 500 105 105 75 65 100
4 112 Rhydon Ground Rock 485 105 130 120 45 45
5 113 Chans… Normal <NA> 450 250 5 5 35 105
6 115 Kanga… Normal <NA> 490 105 95 80 40 80
7 115 Kanga… Normal <NA> 590 105 125 100 60 100
8 131 Lapras Water Ice 535 130 85 80 85 95
9 134 Vapor… Water <NA> 525 130 65 60 110 95
10 143 Snorl… Normal <NA> 540 160 110 65 65 110
# ℹ 57 more rows
# ℹ 3 more variables: Speed <dbl>, Generation <dbl>, Legendary <lgl>Ejercicio 5
Premisa: Aquellos en donde HP > 100 y en donde además Attack > 170.
En Excel
A partir del subset del ejercicio anterior, iremos al menú de la variable Attack y procederemos de la misma manera.
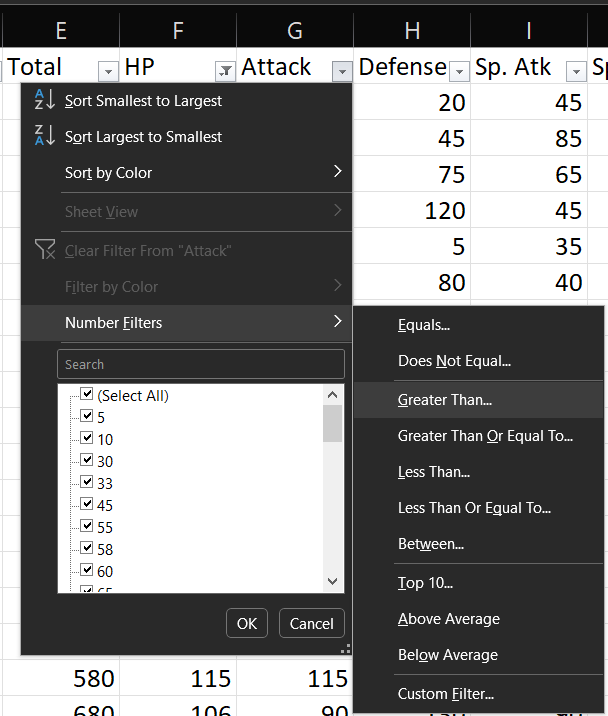
Colocamos nuestro valor de referencia...
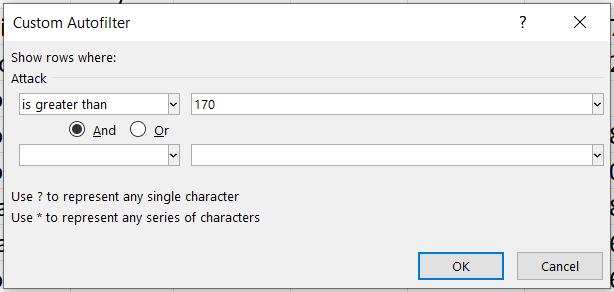
Y observamos que solo 2 pokemones cumplen con ambas condiciones a la vez.

En R
Bastará con usar dos comando de “mayor que” (>) y unirlos con el comando &:
pokemon[pokemon$HP > 100 & pokemon$Attack > 170,]# A tibble: 2 × 13
`#` Name `Type 1` `Type 2` Total HP Attack Defense `Sp. Atk` `Sp. Def`
<dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 150 Mewtwo… Psychic Fighting 780 106 190 100 154 100
2 384 Rayqua… Dragon Flying 780 105 180 100 180 100
# ℹ 3 more variables: Speed <dbl>, Generation <dbl>, Legendary <lgl>En R (funciones de paquete dplyr)
La misma lógica dentro de filter. Sin embargo, ÚNICAMENTE cuando la unión de dos comandos es un Y, podremos listarlos separados por comas:
# Opción 1
pokemon |>
filter(HP > 100 & HP > 170)
# Opción 2
pokemon |>
filter(HP > 100, HP > 170)# A tibble: 3 × 13
`#` Name `Type 1` `Type 2` Total HP Attack Defense `Sp. Atk` `Sp. Def`
<dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 113 Chansey Normal <NA> 450 250 5 5 35 105
2 202 Wobbuf… Psychic <NA> 405 190 33 58 33 58
3 242 Blissey Normal <NA> 540 255 10 10 75 135
# ℹ 3 more variables: Speed <dbl>, Generation <dbl>, Legendary <lgl>Ejercicio 6
Premisa: Aquellos en donde HP > 100, Attack > 170, pero que NO sean de tipo legendario.
En Excel
A partir de los resultados del ejercicio anterior, desplegamos la columna de la variable Legendary y observamos que solo existe el valor TRUE, por lo que si lo deseleccionamos obtendríamos un subset sin ninguna fila. Excel interpreta esto como algo no deseado y automáticamente deshabilita el botón de Aceptar (OK).
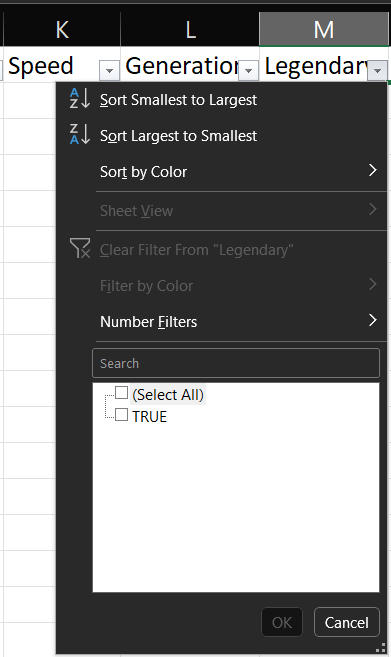
En R
A diferencia de Excel, en R no habrá restricciones en aplicar filtros que nos lleven a tablas con cero filas.
pokemon[pokemon$HP > 100 & pokemon$Attack > 170 & pokemon$Legendary == FALSE,]# A tibble: 0 × 13
# ℹ 13 variables: # <dbl>, Name <chr>, Type 1 <chr>, Type 2 <chr>, Total <dbl>,
# HP <dbl>, Attack <dbl>, Defense <dbl>, Sp. Atk <dbl>, Sp. Def <dbl>,
# Speed <dbl>, Generation <dbl>, Legendary <lgl>Vemos cómo en la cabecera de lo mostrado nos indica A tibble : 0 x 13, es decir, Una tabla con 0 filas y 13 columnas.
En R (funciones de paquete dplyr)
Seguiremos usando la función filter:
pokemon |>
filter(HP > 100,
HP > 170,
Legendary = FALSE)# A tibble: 0 × 13
# ℹ 13 variables: # <dbl>, Name <chr>, Type 1 <chr>, Type 2 <chr>, Total <dbl>,
# HP <dbl>, Attack <dbl>, Defense <dbl>, Sp. Atk <dbl>, Sp. Def <dbl>,
# Speed <dbl>, Generation <dbl>, Legendary <lgl>Una de las ventajas de las funciones de dplyr es que dan mayor facilidad para que nuestros scripts crezcan hacia abajo, en lugar de hacia la derecha (como con los comandos de R base).
Ejercicio 7
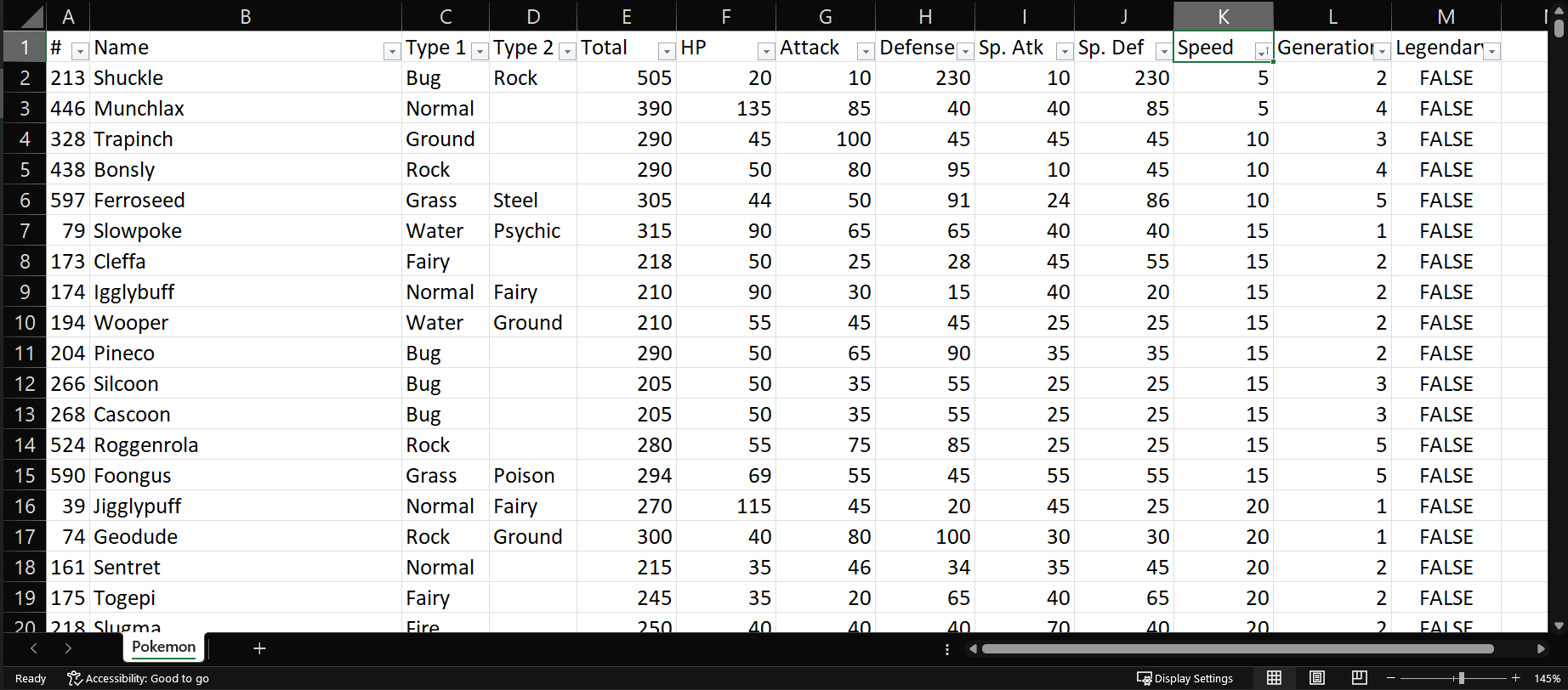
Premisa: Ordenar la tabla según los valores de la variable Speed en forma ascendente.
En Excel
En la ventana desplegable de la variable Speed, seleccionaremos la primera opción para Ordenar de Menor a Mayor.
Ya que esto no produce ningún subset, no se muestra nada al respecto en la parte inferior izquierda.
En R
Para ordenar filas a partir de una o más variables, haremos uso de la función order, la cual realizará por defecto un ordenamiento en forma ascendente:
pokemon[order(pokemon$Speed),]# A tibble: 800 × 13
`#` Name `Type 1` `Type 2` Total HP Attack Defense `Sp. Atk` `Sp. Def`
<dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 213 Shuck… Bug Rock 505 20 10 230 10 230
2 446 Munch… Normal <NA> 390 135 85 40 40 85
3 328 Trapi… Ground <NA> 290 45 100 45 45 45
4 438 Bonsly Rock <NA> 290 50 80 95 10 45
5 597 Ferro… Grass Steel 305 44 50 91 24 86
6 79 Slowp… Water Psychic 315 90 65 65 40 40
7 173 Cleffa Fairy <NA> 218 50 25 28 45 55
8 174 Iggly… Normal Fairy 210 90 30 15 40 20
9 194 Wooper Water Ground 210 55 45 45 25 25
10 204 Pineco Bug <NA> 290 50 65 90 35 35
# ℹ 790 more rows
# ℹ 3 more variables: Speed <dbl>, Generation <dbl>, Legendary <lgl>Dentro de order podemos incluir todas las variables que querramos utilizar para el ordenamiento separadas por comas. Por ejemplo:
pokemon[order(pokemon$Speed, pokemon$HP),]# A tibble: 800 × 13
`#` Name `Type 1` `Type 2` Total HP Attack Defense `Sp. Atk` `Sp. Def`
<dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 213 Shuck… Bug Rock 505 20 10 230 10 230
2 446 Munch… Normal <NA> 390 135 85 40 40 85
3 597 Ferro… Grass Steel 305 44 50 91 24 86
4 328 Trapi… Ground <NA> 290 45 100 45 45 45
5 438 Bonsly Rock <NA> 290 50 80 95 10 45
6 173 Cleffa Fairy <NA> 218 50 25 28 45 55
7 204 Pineco Bug <NA> 290 50 65 90 35 35
8 266 Silco… Bug <NA> 205 50 35 55 25 25
9 268 Casco… Bug <NA> 205 50 35 55 25 25
10 194 Wooper Water Ground 210 55 45 45 25 25
# ℹ 790 more rows
# ℹ 3 more variables: Speed <dbl>, Generation <dbl>, Legendary <lgl>En R (funciones de paquete dplyr)
Dentro del entornor de dplyr, existe la función arrange, que al igual que order, realizará el ordenamiento de forma ascendente por defecto:
pokemon |>
arrange(Speed)# A tibble: 800 × 13
`#` Name `Type 1` `Type 2` Total HP Attack Defense `Sp. Atk` `Sp. Def`
<dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 213 Shuck… Bug Rock 505 20 10 230 10 230
2 446 Munch… Normal <NA> 390 135 85 40 40 85
3 328 Trapi… Ground <NA> 290 45 100 45 45 45
4 438 Bonsly Rock <NA> 290 50 80 95 10 45
5 597 Ferro… Grass Steel 305 44 50 91 24 86
6 79 Slowp… Water Psychic 315 90 65 65 40 40
7 173 Cleffa Fairy <NA> 218 50 25 28 45 55
8 174 Iggly… Normal Fairy 210 90 30 15 40 20
9 194 Wooper Water Ground 210 55 45 45 25 25
10 204 Pineco Bug <NA> 290 50 65 90 35 35
# ℹ 790 more rows
# ℹ 3 more variables: Speed <dbl>, Generation <dbl>, Legendary <lgl>Del mismo modo, dentro de arrange podemos incluir una o más variables:
pokemon |>
arrange(Speed, HP)# A tibble: 800 × 13
`#` Name `Type 1` `Type 2` Total HP Attack Defense `Sp. Atk` `Sp. Def`
<dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 213 Shuck… Bug Rock 505 20 10 230 10 230
2 446 Munch… Normal <NA> 390 135 85 40 40 85
3 597 Ferro… Grass Steel 305 44 50 91 24 86
4 328 Trapi… Ground <NA> 290 45 100 45 45 45
5 438 Bonsly Rock <NA> 290 50 80 95 10 45
6 173 Cleffa Fairy <NA> 218 50 25 28 45 55
7 204 Pineco Bug <NA> 290 50 65 90 35 35
8 266 Silco… Bug <NA> 205 50 35 55 25 25
9 268 Casco… Bug <NA> 205 50 35 55 25 25
10 194 Wooper Water Ground 210 55 45 45 25 25
# ℹ 790 more rows
# ℹ 3 more variables: Speed <dbl>, Generation <dbl>, Legendary <lgl>
El orden de los factores sí importa
Tanto con order cuanto con arrange, el orden en el que indiquemos las variables influirá en la tabla resultado:
# Esto...
pokemon[order(pokemon$Speed, pokemon$HP),]
# ...no da el mismo resultado que esto
pokemon[order(pokemon$HP, pokemon$Speed),]Ejercicio 8
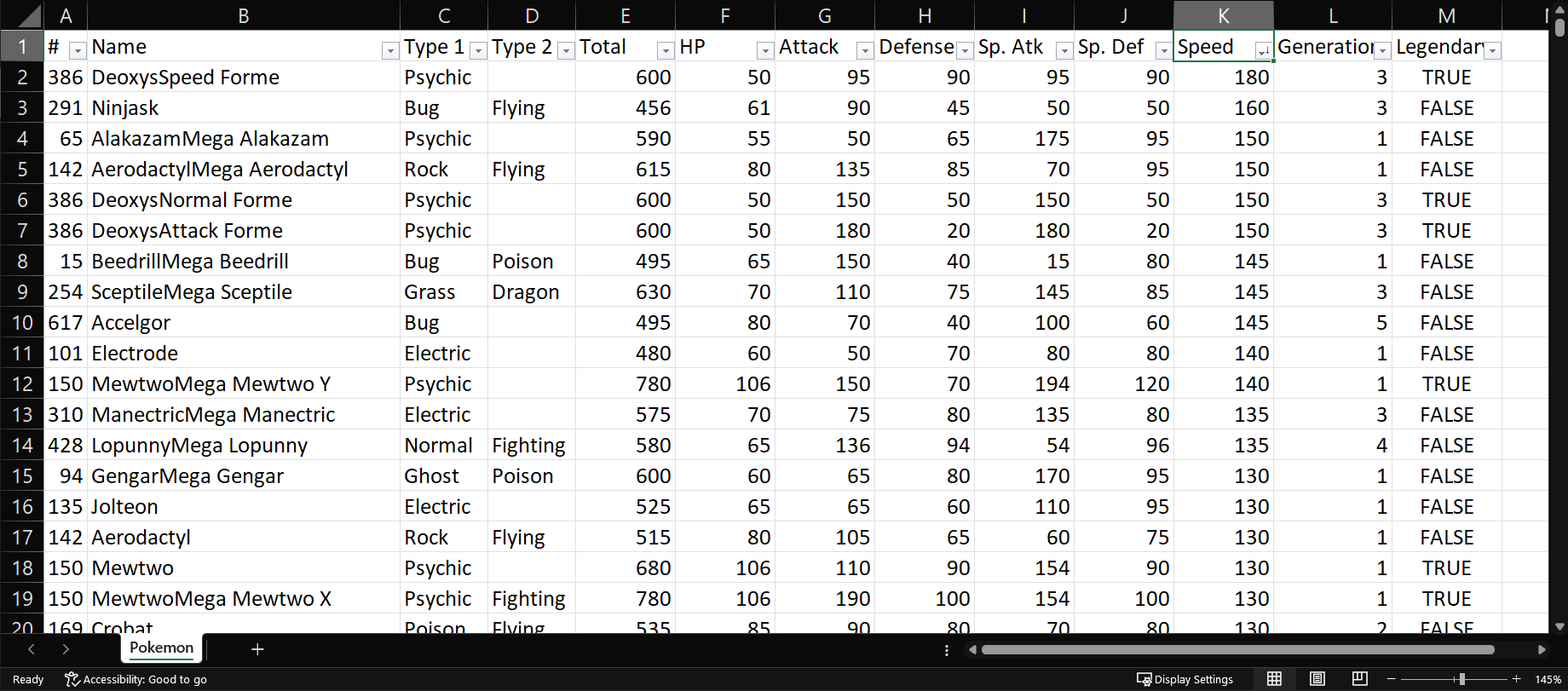
Premisa: Ordenar la tabla según los valores de la variable Speed en forma descendente.
En Excel
De forma similar al ejercicio anterior, seleccionaremos la opción de De Mayor a Menor en el menú de la variable Speed.
La tabla resultante:
En R
Seguiremos usando order, pero cambiaremos el valor del argumento decreasing:
pokemon[order(pokemon$Speed, decreasing = TRUE),]# A tibble: 800 × 13
`#` Name `Type 1` `Type 2` Total HP Attack Defense `Sp. Atk` `Sp. Def`
<dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 386 Deoxy… Psychic <NA> 600 50 95 90 95 90
2 291 Ninja… Bug Flying 456 61 90 45 50 50
3 65 Alaka… Psychic <NA> 590 55 50 65 175 95
4 142 Aerod… Rock Flying 615 80 135 85 70 95
5 386 Deoxy… Psychic <NA> 600 50 150 50 150 50
6 386 Deoxy… Psychic <NA> 600 50 180 20 180 20
7 15 Beedr… Bug Poison 495 65 150 40 15 80
8 254 Scept… Grass Dragon 630 70 110 75 145 85
9 617 Accel… Bug <NA> 495 80 70 40 100 60
10 101 Elect… Electric <NA> 480 60 50 70 80 80
# ℹ 790 more rows
# ℹ 3 more variables: Speed <dbl>, Generation <dbl>, Legendary <lgl>En R (funciones de paquete dplyr)
En el caso de arrange, para ordenar de forma descendente, aplicaremos una función dentro de arrange llamada desc del siguiente modo:
pokemon |>
arrange(desc(Speed))# A tibble: 800 × 13
`#` Name `Type 1` `Type 2` Total HP Attack Defense `Sp. Atk` `Sp. Def`
<dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 386 Deoxy… Psychic <NA> 600 50 95 90 95 90
2 291 Ninja… Bug Flying 456 61 90 45 50 50
3 65 Alaka… Psychic <NA> 590 55 50 65 175 95
4 142 Aerod… Rock Flying 615 80 135 85 70 95
5 386 Deoxy… Psychic <NA> 600 50 150 50 150 50
6 386 Deoxy… Psychic <NA> 600 50 180 20 180 20
7 15 Beedr… Bug Poison 495 65 150 40 15 80
8 254 Scept… Grass Dragon 630 70 110 75 145 85
9 617 Accel… Bug <NA> 495 80 70 40 100 60
10 101 Elect… Electric <NA> 480 60 50 70 80 80
# ℹ 790 more rows
# ℹ 3 more variables: Speed <dbl>, Generation <dbl>, Legendary <lgl>La ventaja de esta sintaxis, es que permite manejar el orden de cada variable dentro de arrange de forma independiente, i.e. si no lleva nada, se hará un ordenamiento ascendente y si lleva desc lo hara de forma descendente. Por ejemplo:
pokemon |>
arrange(Speed, desc(HP))# A tibble: 800 × 13
`#` Name `Type 1` `Type 2` Total HP Attack Defense `Sp. Atk` `Sp. Def`
<dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 446 Munch… Normal <NA> 390 135 85 40 40 85
2 213 Shuck… Bug Rock 505 20 10 230 10 230
3 438 Bonsly Rock <NA> 290 50 80 95 10 45
4 328 Trapi… Ground <NA> 290 45 100 45 45 45
5 597 Ferro… Grass Steel 305 44 50 91 24 86
6 79 Slowp… Water Psychic 315 90 65 65 40 40
7 174 Iggly… Normal Fairy 210 90 30 15 40 20
8 590 Foong… Grass Poison 294 69 55 45 55 55
9 194 Wooper Water Ground 210 55 45 45 25 25
10 524 Rogge… Rock <NA> 280 55 75 85 25 25
# ℹ 790 more rows
# ℹ 3 more variables: Speed <dbl>, Generation <dbl>, Legendary <lgl>Ejercicio 9
Premisa: Ordenar la tabla según los valores de la variable Speed en forma descendente y seleccionar los 20 primeros resultados.
En Excel
Partiremos de los resultados del ejercicio anterior y luego seleccionaremos todas las filas desde la 22 (recordemos que la fila 1 contiene los nombres de columnas).
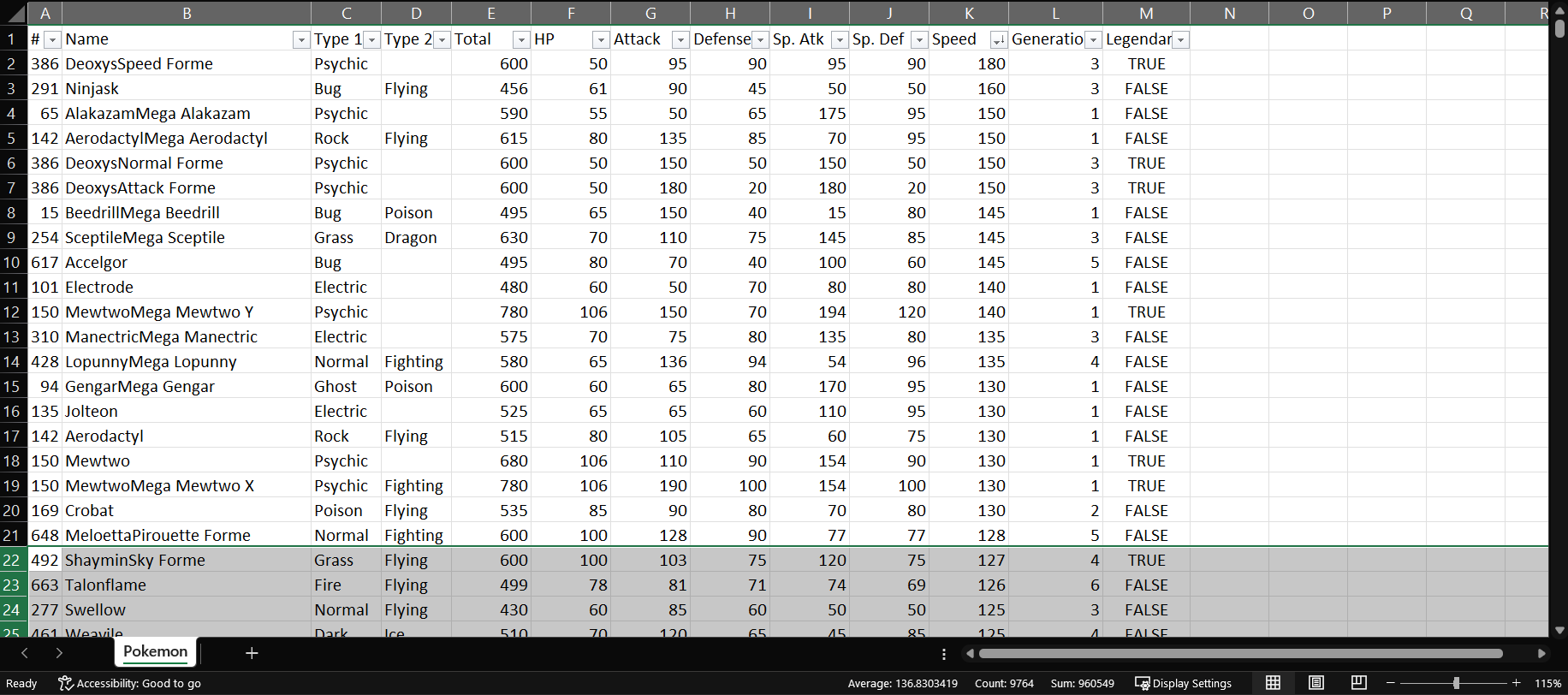
A continuación, presionaremos la tecla Supr (o Del) y así nos quedaremos con solo las primeras 20 filas en nuestra tabla ordenada.
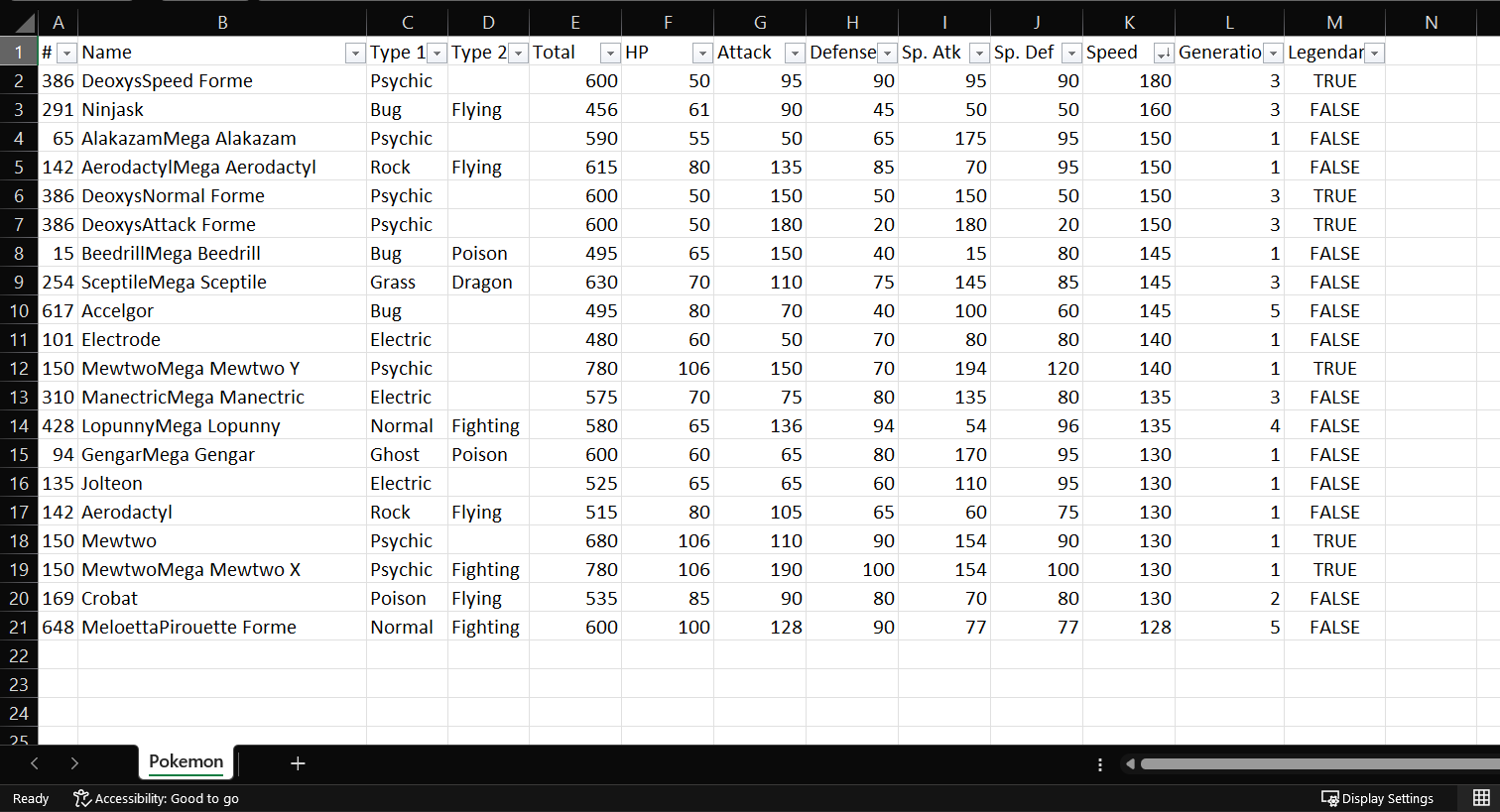
En R
En R base, usaremos dos líneas de código, una para el ordenamiento (la misma que en el ejercicio anterior) y otra en donde haremos un subset de las primeras 20 filas:
ejercicio_9 <- pokemon[order(pokemon$Speed, decreasing = TRUE),]
ejercicio_9[1:20,]# A tibble: 20 × 13
`#` Name `Type 1` `Type 2` Total HP Attack Defense `Sp. Atk` `Sp. Def`
<dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 386 Deoxy… Psychic <NA> 600 50 95 90 95 90
2 291 Ninja… Bug Flying 456 61 90 45 50 50
3 65 Alaka… Psychic <NA> 590 55 50 65 175 95
4 142 Aerod… Rock Flying 615 80 135 85 70 95
5 386 Deoxy… Psychic <NA> 600 50 150 50 150 50
6 386 Deoxy… Psychic <NA> 600 50 180 20 180 20
7 15 Beedr… Bug Poison 495 65 150 40 15 80
8 254 Scept… Grass Dragon 630 70 110 75 145 85
9 617 Accel… Bug <NA> 495 80 70 40 100 60
10 101 Elect… Electric <NA> 480 60 50 70 80 80
11 150 Mewtw… Psychic <NA> 780 106 150 70 194 120
12 310 Manec… Electric <NA> 575 70 75 80 135 80
13 428 Lopun… Normal Fighting 580 65 136 94 54 96
14 94 Genga… Ghost Poison 600 60 65 80 170 95
15 135 Jolte… Electric <NA> 525 65 65 60 110 95
16 142 Aerod… Rock Flying 515 80 105 65 60 75
17 150 Mewtwo Psychic <NA> 680 106 110 90 154 90
18 150 Mewtw… Psychic Fighting 780 106 190 100 154 100
19 169 Crobat Poison Flying 535 85 90 80 70 80
20 648 Meloe… Normal Fighting 600 100 128 90 77 77
# ℹ 3 more variables: Speed <dbl>, Generation <dbl>, Legendary <lgl>En R (funciones de paquete dplyr)
A partir de lo utilizado en el ejercicio anterior, añadiremos un paso adicional utilizando la función slice que permite realizar subsets utilizando como argumentos vectores numéricos en donde indicamos las filas que deseamos mantener:
pokemon |>
arrange(desc(Speed)) |>
slice(1:20)# A tibble: 20 × 13
`#` Name `Type 1` `Type 2` Total HP Attack Defense `Sp. Atk` `Sp. Def`
<dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 386 Deoxy… Psychic <NA> 600 50 95 90 95 90
2 291 Ninja… Bug Flying 456 61 90 45 50 50
3 65 Alaka… Psychic <NA> 590 55 50 65 175 95
4 142 Aerod… Rock Flying 615 80 135 85 70 95
5 386 Deoxy… Psychic <NA> 600 50 150 50 150 50
6 386 Deoxy… Psychic <NA> 600 50 180 20 180 20
7 15 Beedr… Bug Poison 495 65 150 40 15 80
8 254 Scept… Grass Dragon 630 70 110 75 145 85
9 617 Accel… Bug <NA> 495 80 70 40 100 60
10 101 Elect… Electric <NA> 480 60 50 70 80 80
11 150 Mewtw… Psychic <NA> 780 106 150 70 194 120
12 310 Manec… Electric <NA> 575 70 75 80 135 80
13 428 Lopun… Normal Fighting 580 65 136 94 54 96
14 94 Genga… Ghost Poison 600 60 65 80 170 95
15 135 Jolte… Electric <NA> 525 65 65 60 110 95
16 142 Aerod… Rock Flying 515 80 105 65 60 75
17 150 Mewtwo Psychic <NA> 680 106 110 90 154 90
18 150 Mewtw… Psychic Fighting 780 106 190 100 154 100
19 169 Crobat Poison Flying 535 85 90 80 70 80
20 648 Meloe… Normal Fighting 600 100 128 90 77 77
# ℹ 3 more variables: Speed <dbl>, Generation <dbl>, Legendary <lgl>Ejercicio 10
Premisa: Ordenar la tabla según una variable nueva que consista en el cociente entre HP y Attack en forma descendente.
En Excel
Para este último ejercicio, será necesario crear una nueva columna en donde colocaremos la fórmula =F2/G2, lo cual hace referencia a las variables HP y Attack en la primera fila con valores (la fila 2).
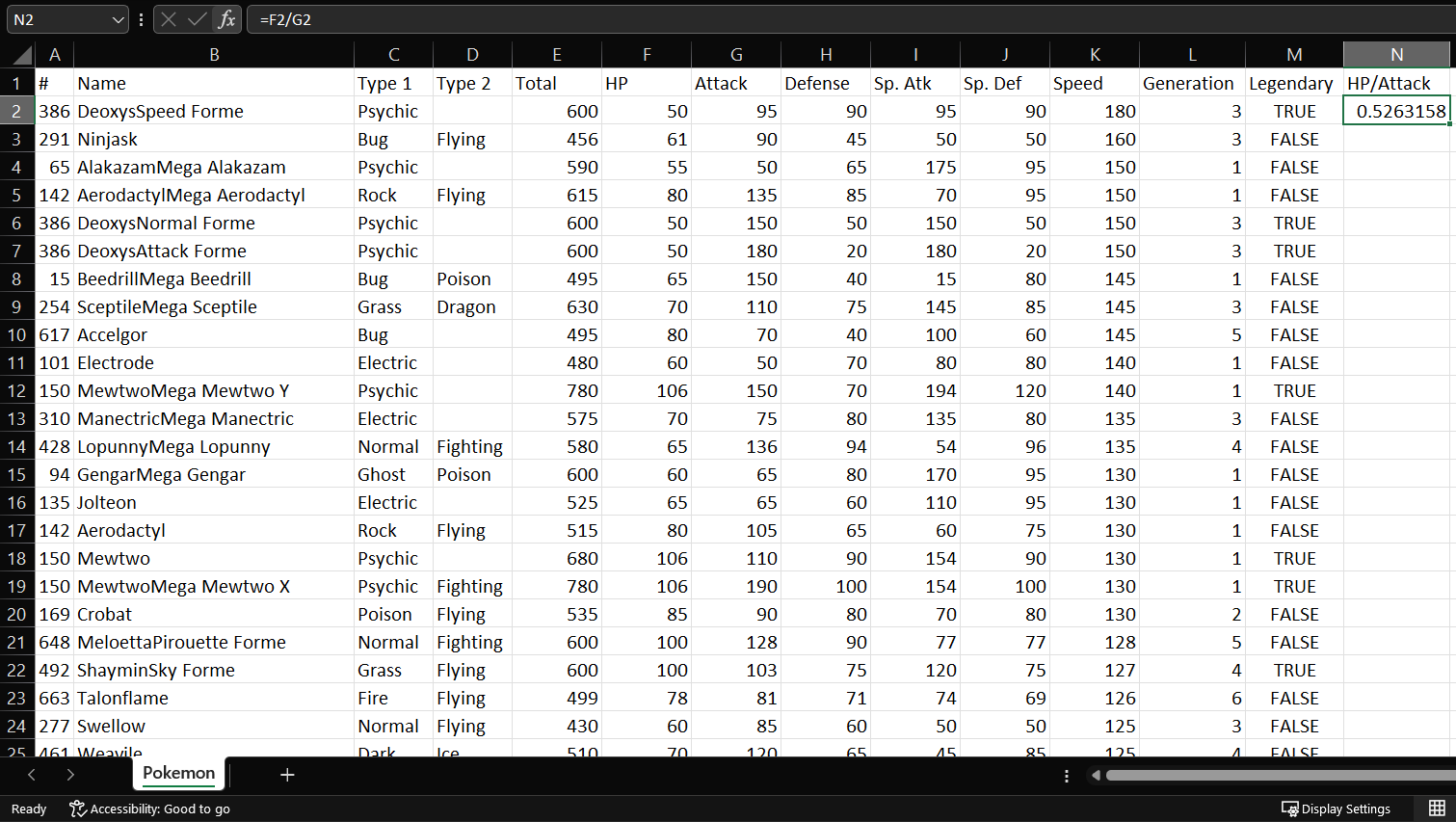
Luego, notaremos que en la esquina inferior derecha de la celda que contiene nuestro nuevo valor hay un pequeño cuadradito verde.
Al posicionar el cursor sobre ese cuadradito cambiará su forma (una cruz engrosada) y al dar doble click sobre él, veremos cómo la fórmula se extiende sobre el resto de celdas hacia abajo, generando los valores correspondientes para cada fila.
Ahora ya solo nos queda aplicar los filtros sobre dicha columna, desplegar su menú correspondiente y elegir la opción de Mayor a menor (orden descendente).
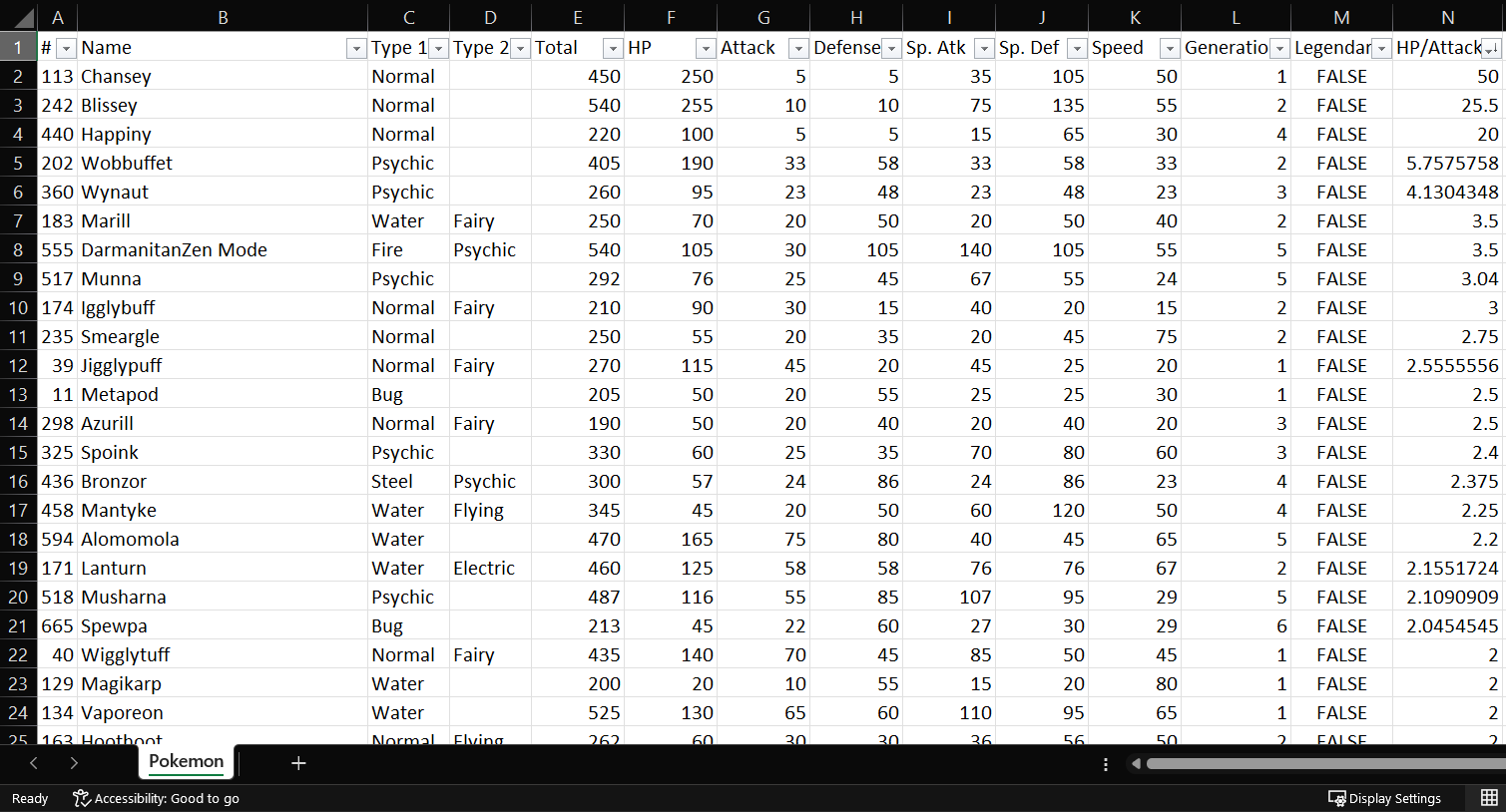
La tabla resultante:
En R
En R base, la generación explícita de una nueva variable es opcional, ya que el cálculo y la indexación pueden hacerse en una misma línea de código.
# Opción 1
# Sin necesidad de crear una nueva variable
pokemon[order(pokemon$HP/pokemon$Attack, decreasing = TRUE),]# A tibble: 800 × 13
`#` Name `Type 1` `Type 2` Total HP Attack Defense `Sp. Atk` `Sp. Def`
<dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 113 Chans… Normal <NA> 450 250 5 5 35 105
2 242 Bliss… Normal <NA> 540 255 10 10 75 135
3 440 Happi… Normal <NA> 220 100 5 5 15 65
4 202 Wobbu… Psychic <NA> 405 190 33 58 33 58
5 360 Wynaut Psychic <NA> 260 95 23 48 23 48
6 183 Marill Water Fairy 250 70 20 50 20 50
7 555 Darma… Fire Psychic 540 105 30 105 140 105
8 517 Munna Psychic <NA> 292 76 25 45 67 55
9 174 Iggly… Normal Fairy 210 90 30 15 40 20
10 235 Smear… Normal <NA> 250 55 20 35 20 45
# ℹ 790 more rows
# ℹ 3 more variables: Speed <dbl>, Generation <dbl>, Legendary <lgl>En R (funciones de paquete dplyr)
Usaremos el mismo enfoque que en el ejercicio anterior:
pokemon |>
arrange(desc(HP/Attack))# A tibble: 800 × 13
`#` Name `Type 1` `Type 2` Total HP Attack Defense `Sp. Atk` `Sp. Def`
<dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 113 Chans… Normal <NA> 450 250 5 5 35 105
2 242 Bliss… Normal <NA> 540 255 10 10 75 135
3 440 Happi… Normal <NA> 220 100 5 5 15 65
4 202 Wobbu… Psychic <NA> 405 190 33 58 33 58
5 360 Wynaut Psychic <NA> 260 95 23 48 23 48
6 183 Marill Water Fairy 250 70 20 50 20 50
7 555 Darma… Fire Psychic 540 105 30 105 140 105
8 517 Munna Psychic <NA> 292 76 25 45 67 55
9 174 Iggly… Normal Fairy 210 90 30 15 40 20
10 235 Smear… Normal <NA> 250 55 20 35 20 45
# ℹ 790 more rows
# ℹ 3 more variables: Speed <dbl>, Generation <dbl>, Legendary <lgl>
¿Y qué si quisiera crear una nueva variable?
En R base, es tan sencillo como usar el comando de asignación:
pokemon$HP_Attack <- pokemon$HP/pokemon$AttackCon dplyr, la función para añadir nuevas variables es mutate:
pokemon |>
mutate(HP_Attack = HP/Attack)# A tibble: 800 × 14
`#` Name `Type 1` `Type 2` Total HP Attack Defense `Sp. Atk` `Sp. Def`
<dbl> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 1 Bulba… Grass Poison 318 45 49 49 65 65
2 2 Ivysa… Grass Poison 405 60 62 63 80 80
3 3 Venus… Grass Poison 525 80 82 83 100 100
4 3 Venus… Grass Poison 625 80 100 123 122 120
5 4 Charm… Fire <NA> 309 39 52 43 60 50
6 5 Charm… Fire <NA> 405 58 64 58 80 65
7 6 Chari… Fire Flying 534 78 84 78 109 85
8 6 Chari… Fire Dragon 634 78 130 111 130 85
9 6 Chari… Fire Flying 634 78 104 78 159 115
10 7 Squir… Water <NA> 314 44 48 65 50 64
# ℹ 790 more rows
# ℹ 4 more variables: Speed <dbl>, Generation <dbl>, Legendary <lgl>,
# HP_Attack <dbl>