require(readxl)
require(dplyr)
clientes <- read_excel(path = "datos-clientes.xlsx", sheet = 1) %>%
# Convertir variable 'nacimiento' a clase Date
mutate(nacimiento = as.Date(nacimiento))¿Cómo filtrar datos en Excel y R? (Parte 2: Cadenas de texto)
Explora nuestros posts y nuestros cursos
Aprender a filtrar cadenas de texto es una habilidad esencial para cualquier persona que trabaje con datos. Las cadenas de texto son una forma común de representar información en los datos, y el filtrado puede ayudarnos a extraer información relevante de los datos. El filtrado de cadenas de texto puede utilizarse para identificar datos específicos, eliminar datos innecesarios o comprobar la calidad de los datos. Es una habilidad que se puede aprender rápidamente y que puede ser utilizada para una variedad de propósitos.
Acerca de la información
Para este artículo, utilizaremos como ejemplo el archivo datos_clientes.xlsx en donde contamos con un listado de información de 5000 clientes ficticios. Esta tabla fue generada de manera aleatoria a través de un script en R (link), por lo que puede ser utilizada sin problemas. Para cargar nuestra tabla, usaremos las herramientas del paquete readxl (puedes revisar los detalles en nuestro artículo ¿Cómo cargar (leer) una tabla de Excel en R?).
En este artículo, utilizaremos las herramientas de manejo de datos del paquete dplyr, y abordaremos el tema a partir de 6 ejercicios:
Ejercicio 1
Premisa: Mostrar los clientes en donde uno de sus nombres sea Irene.
En Excel
Iniciaremos seleccionando las celdas cabecera de nuestra tabla y dando click al botón Filtro en la pestaña Datos.
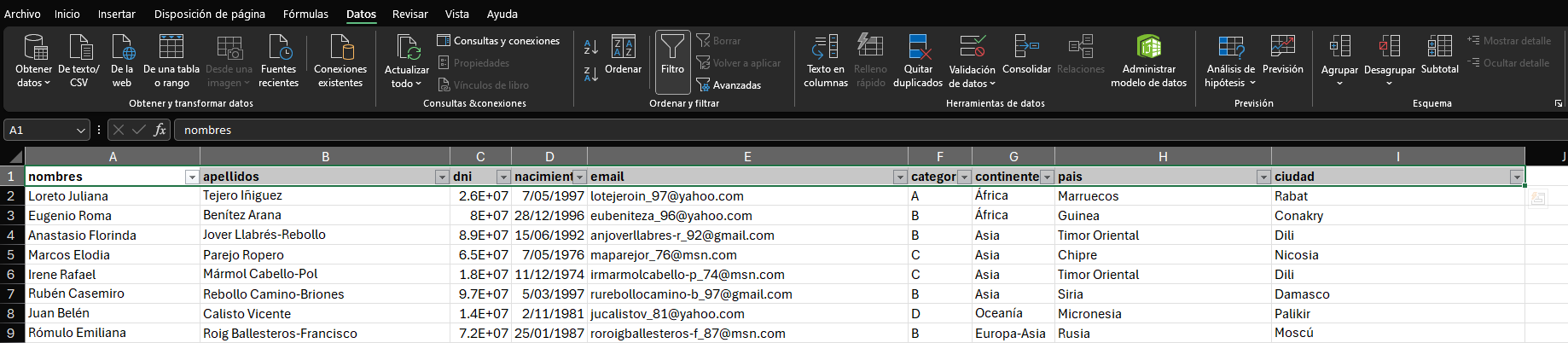
A continuación, desplegaremos el menú de filtros de la columna nombres, luego iremos a la opción Filtros de texto y finalmente seleccionaremos la opción Contiene.
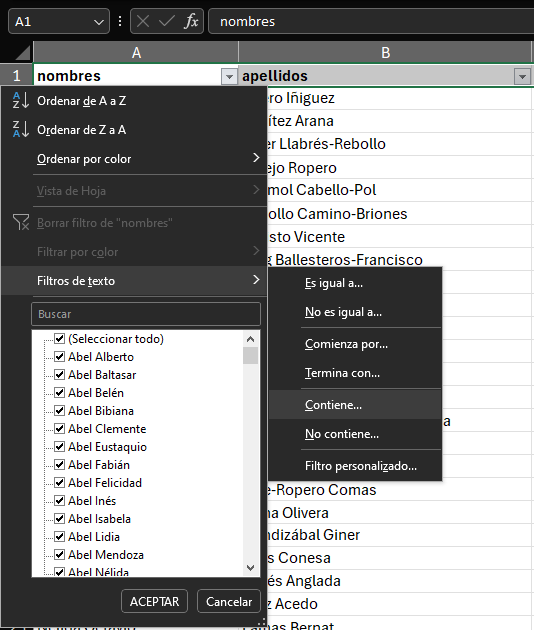
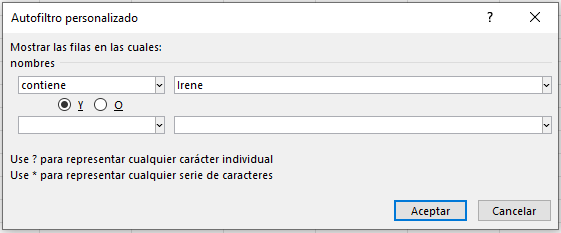
Se abrirá una pequeña ventana (llamada Autofiltro personalizado) en donde podremos colocar el texto que deseamos buscar. En nuestro caso, la palabra Irene. Click en Aceptar.
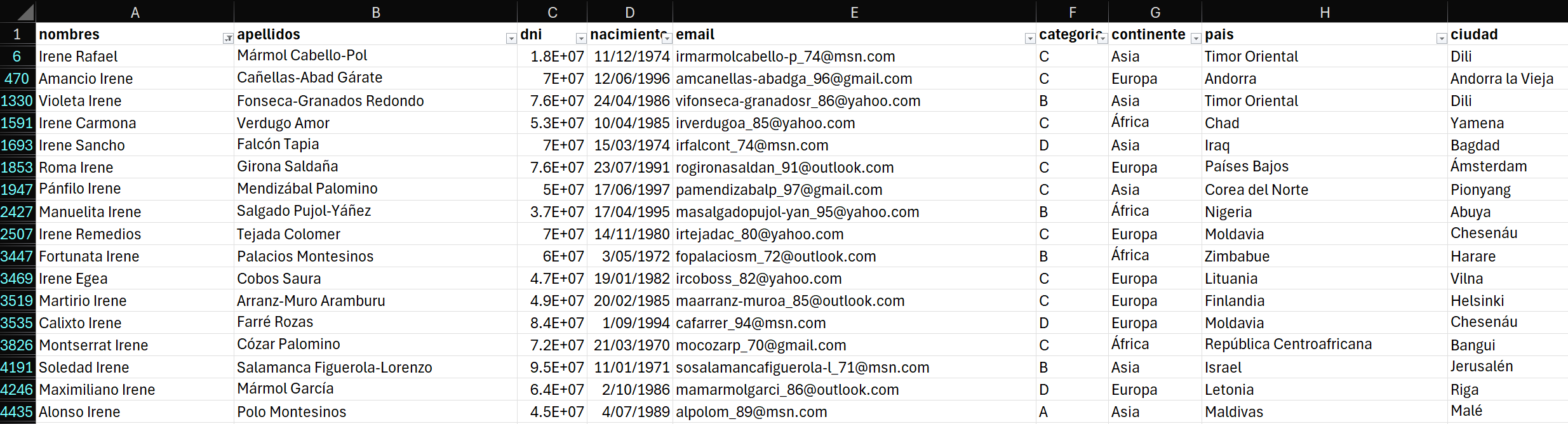
Vemos como resultado una tabla de 17 filas.
En R
Utilizaremos la función grep, la cual toma un vector de caracteres, un patrón de texto y nos devuelve un vector numérico con las posiciones en donde el patrón se cumpla:
posiciones_1 <- grep(x = clientes$nombres, pattern = "Irene")Como se ve, hemos almacenado los valores en un objeto llamado posiciones_1, el cual usaremos para indexar nuestra tabla ya sea a través de la sintaxis de R base:
clientes[posiciones_1,]# A tibble: 17 × 9
nombres apellidos dni nacimiento email categoria continente pais ciudad
<chr> <chr> <dbl> <date> <chr> <chr> <chr> <chr> <chr>
1 Irene Ra… Mármol C… 1.83e7 1974-12-11 irma… C Asia Timo… Dili
2 Amancio … Cañellas… 7.00e7 1996-06-12 amca… C Europa Ando… Andor…
3 Violeta … Fonseca-… 7.58e7 1986-04-24 vifo… B Asia Timo… Dili
4 Irene Ca… Verdugo … 5.30e7 1985-04-10 irve… C África Chad Yamena
5 Irene Sa… Falcón T… 7.04e7 1974-03-15 irfa… D Asia Iraq Bagdad
6 Roma Ire… Girona S… 7.63e7 1991-07-23 rogi… C Europa País… Ámste…
7 Pánfilo … Mendizáb… 5.02e7 1997-06-17 pame… C Asia Core… Piony…
8 Manuelit… Salgado … 3.66e7 1995-04-17 masa… B África Nige… Abuya
9 Irene Re… Tejada C… 7.02e7 1980-11-14 irte… C Europa Mold… Chese…
10 Fortunat… Palacios… 6.02e7 1972-05-03 fopa… B África Zimb… Harare
11 Irene Eg… Cobos Sa… 4.69e7 1982-01-19 irco… C Europa Litu… Vilna
12 Martirio… Arranz-M… 4.88e7 1985-02-20 maar… C Europa Finl… Helsi…
13 Calixto … Farré Ro… 8.45e7 1994-09-01 cafa… D Europa Mold… Chese…
14 Montserr… Cózar Pa… 7.23e7 1970-03-21 moco… C África Repú… Bangui
15 Soledad … Salamanc… 9.48e7 1971-01-11 sosa… B Asia Isra… Jerus…
16 Maximili… Mármol G… 6.37e7 1986-10-02 mama… D Europa Leto… Riga
17 Alonso I… Polo Mon… 4.50e7 1989-07-04 alpo… A Asia Mald… Malé …o usando las herramientas de dplyr:
clientes |>
slice(posiciones_1)# A tibble: 17 × 9
nombres apellidos dni nacimiento email categoria continente pais ciudad
<chr> <chr> <dbl> <date> <chr> <chr> <chr> <chr> <chr>
1 Irene Ra… Mármol C… 1.83e7 1974-12-11 irma… C Asia Timo… Dili
2 Amancio … Cañellas… 7.00e7 1996-06-12 amca… C Europa Ando… Andor…
3 Violeta … Fonseca-… 7.58e7 1986-04-24 vifo… B Asia Timo… Dili
4 Irene Ca… Verdugo … 5.30e7 1985-04-10 irve… C África Chad Yamena
5 Irene Sa… Falcón T… 7.04e7 1974-03-15 irfa… D Asia Iraq Bagdad
6 Roma Ire… Girona S… 7.63e7 1991-07-23 rogi… C Europa País… Ámste…
7 Pánfilo … Mendizáb… 5.02e7 1997-06-17 pame… C Asia Core… Piony…
8 Manuelit… Salgado … 3.66e7 1995-04-17 masa… B África Nige… Abuya
9 Irene Re… Tejada C… 7.02e7 1980-11-14 irte… C Europa Mold… Chese…
10 Fortunat… Palacios… 6.02e7 1972-05-03 fopa… B África Zimb… Harare
11 Irene Eg… Cobos Sa… 4.69e7 1982-01-19 irco… C Europa Litu… Vilna
12 Martirio… Arranz-M… 4.88e7 1985-02-20 maar… C Europa Finl… Helsi…
13 Calixto … Farré Ro… 8.45e7 1994-09-01 cafa… D Europa Mold… Chese…
14 Montserr… Cózar Pa… 7.23e7 1970-03-21 moco… C África Repú… Bangui
15 Soledad … Salamanc… 9.48e7 1971-01-11 sosa… B Asia Isra… Jerus…
16 Maximili… Mármol G… 6.37e7 1986-10-02 mama… D Europa Leto… Riga
17 Alonso I… Polo Mon… 4.50e7 1989-07-04 alpo… A Asia Mald… Malé
Filtros básicos - Parte 1
No olvides revisar nuestra publicación ¿Cómo filtrar datos en Excel y R? (Parte 1: filtros básicos) en donde mostramos detallamos el uso de los operadores [] y de las funciones filter y slice.
Es importante recalcar que solo por cuestiones didácticas estamos creando un objeto para almacenar las posiciones de las filas (posiciones_1), pero esto no es indispensable, por lo que también puedes usar grep directamente dentro de los procesos de filtrado:
clientes[grep(x = clientes$nombres, pattern = "Irene"),]
clientes |>
slice(grep(x = nombres, pattern = "Irene"))
Mayúsculas y minúsculas NO son lo mismo
A diferencia de Excel, cuando trabajamos con funciones que toman patrones de texto, es MUY importante que tengamos en mente que un texto escrito en minúsculas será considerado distinto a si lo está en mayúsculas.
Por ejemplo, si usamos irene (todo minúsculas) como patrón de búsqueda:
clientes |>
slice(grep(x = nombres, pattern = "irene"))# A tibble: 0 × 9
# ℹ 9 variables: nombres <chr>, apellidos <chr>, dni <dbl>, nacimiento <date>,
# email <chr>, categoria <chr>, continente <chr>, pais <chr>, ciudad <chr>Obtendremos una tabla sin filas, ya que no existe ningún caso en donde aparezca exactamente el texto irene.
Para indicarle a grep que NO tome en cuenta minúsculas y mayúsculas en el patrón dado, podemos usar el argumento ignore.case = TRUE:
clientes |>
slice(grep(x = nombres, pattern = "irene", ignore.case = TRUE))# A tibble: 17 × 9
nombres apellidos dni nacimiento email categoria continente pais ciudad
<chr> <chr> <dbl> <date> <chr> <chr> <chr> <chr> <chr>
1 Irene Ra… Mármol C… 1.83e7 1974-12-11 irma… C Asia Timo… Dili
2 Amancio … Cañellas… 7.00e7 1996-06-12 amca… C Europa Ando… Andor…
3 Violeta … Fonseca-… 7.58e7 1986-04-24 vifo… B Asia Timo… Dili
4 Irene Ca… Verdugo … 5.30e7 1985-04-10 irve… C África Chad Yamena
5 Irene Sa… Falcón T… 7.04e7 1974-03-15 irfa… D Asia Iraq Bagdad
6 Roma Ire… Girona S… 7.63e7 1991-07-23 rogi… C Europa País… Ámste…
7 Pánfilo … Mendizáb… 5.02e7 1997-06-17 pame… C Asia Core… Piony…
8 Manuelit… Salgado … 3.66e7 1995-04-17 masa… B África Nige… Abuya
9 Irene Re… Tejada C… 7.02e7 1980-11-14 irte… C Europa Mold… Chese…
10 Fortunat… Palacios… 6.02e7 1972-05-03 fopa… B África Zimb… Harare
11 Irene Eg… Cobos Sa… 4.69e7 1982-01-19 irco… C Europa Litu… Vilna
12 Martirio… Arranz-M… 4.88e7 1985-02-20 maar… C Europa Finl… Helsi…
13 Calixto … Farré Ro… 8.45e7 1994-09-01 cafa… D Europa Mold… Chese…
14 Montserr… Cózar Pa… 7.23e7 1970-03-21 moco… C África Repú… Bangui
15 Soledad … Salamanc… 9.48e7 1971-01-11 sosa… B Asia Isra… Jerus…
16 Maximili… Mármol G… 6.37e7 1986-10-02 mama… D Europa Leto… Riga
17 Alonso I… Polo Mon… 4.50e7 1989-07-04 alpo… A Asia Mald… Malé Ejercicio 2
Premisa: Mostrar los clientes cuyo PRIMER nombre sea Irene.
En Excel
Para este caso, volveremos a abrir la ventana de Autofiltro personalizado, pero esta vez seleccionaremos la opción Comienza por:

Veremos como resultado una tabla con 5 registros:

En R
Volveremos a utilizar la función grep, pero esta vez indicaremos que la palabra Irene debe estar al inicio. Para ello, haremos uso del símbolo ^ justo antes de la palabra:
posiciones_2 <- grep(x = clientes$nombres, pattern = "^Irene")Y, de nuevo, aplicaremos el filtrado en cualquiera de las dos formas aprendidas:
clientes[posiciones_2,]
clientes |>
slice(posiciones_2)# A tibble: 5 × 9
nombres apellidos dni nacimiento email categoria continente pais ciudad
<chr> <chr> <dbl> <date> <chr> <chr> <chr> <chr> <chr>
1 Irene Raf… Mármol C… 1.83e7 1974-12-11 irma… C Asia Timo… Dili
2 Irene Car… Verdugo … 5.30e7 1985-04-10 irve… C África Chad Yamena
3 Irene San… Falcón T… 7.04e7 1974-03-15 irfa… D Asia Iraq Bagdad
4 Irene Rem… Tejada C… 7.02e7 1980-11-14 irte… C Europa Mold… Chese…
5 Irene Egea Cobos Sa… 4.69e7 1982-01-19 irco… C Europa Litu… Vilna Ejercicio 3
Premisa: Mostrar los clientes cuyo SEGUNDO nombre sea Irene.
En Excel
Para este caso, volveremos a abrir la ventana de Autofiltro personalizado, pero esta vez seleccionaremos la opción Termina con:
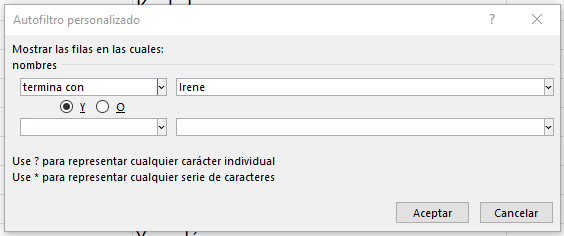
Veremos como resultado una tabla con 12 registros:

En R
De forma similar a lo anterior, pero esta vez usaremos el símbolo $ LUEGO de la palabra Irene para indicar que deseamos indexar aquellas cadenas que TERMINEN con esa palabra:
posiciones_3 <- grep(x = clientes$nombres, pattern = "Irene$")Y, de nuevo, aplicaremos el filtrado en cualquiera de las dos formas aprendidas:
clientes[posiciones_3,]
clientes |>
slice(posiciones_3)# A tibble: 12 × 9
nombres apellidos dni nacimiento email categoria continente pais ciudad
<chr> <chr> <dbl> <date> <chr> <chr> <chr> <chr> <chr>
1 Amancio … Cañellas… 7.00e7 1996-06-12 amca… C Europa Ando… Andor…
2 Violeta … Fonseca-… 7.58e7 1986-04-24 vifo… B Asia Timo… Dili
3 Roma Ire… Girona S… 7.63e7 1991-07-23 rogi… C Europa País… Ámste…
4 Pánfilo … Mendizáb… 5.02e7 1997-06-17 pame… C Asia Core… Piony…
5 Manuelit… Salgado … 3.66e7 1995-04-17 masa… B África Nige… Abuya
6 Fortunat… Palacios… 6.02e7 1972-05-03 fopa… B África Zimb… Harare
7 Martirio… Arranz-M… 4.88e7 1985-02-20 maar… C Europa Finl… Helsi…
8 Calixto … Farré Ro… 8.45e7 1994-09-01 cafa… D Europa Mold… Chese…
9 Montserr… Cózar Pa… 7.23e7 1970-03-21 moco… C África Repú… Bangui
10 Soledad … Salamanc… 9.48e7 1971-01-11 sosa… B Asia Isra… Jerus…
11 Maximili… Mármol G… 6.37e7 1986-10-02 mama… D Europa Leto… Riga
12 Alonso I… Polo Mon… 4.50e7 1989-07-04 alpo… A Asia Mald… Malé Ejercicio 4
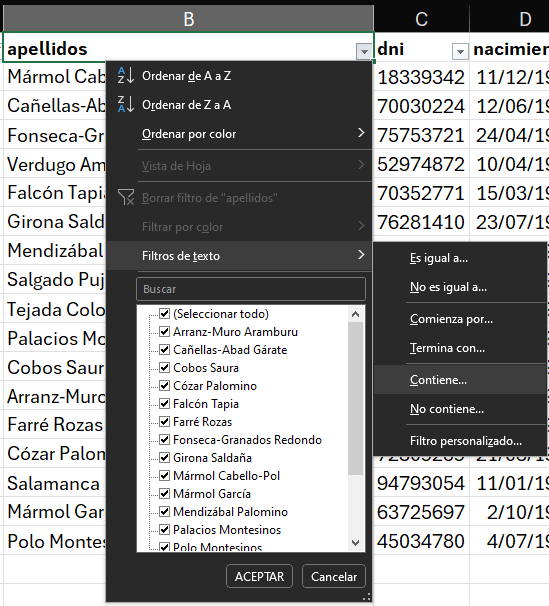
Premisa: Mostrar los clientes en donde uno de sus nombres sea Irene Y en donde uno de sus apellidos sea Polo.
En Excel
Repetiremos todos los pasos del Ejercicio 1 y luego de eso volveremos a abrir la ventana de Autofiltro personalizado pero en la columna apellidos, para luego seleccionar la opción Contiene:
Se volverá a abrir la ventana de Autofiltro personalizado y colocaremos el apellido de interés Polo.
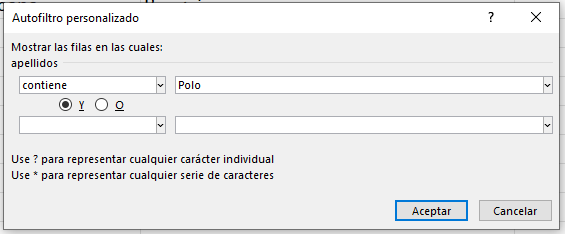
Obtendremos como resultado un único registro:

En R
Para este caso, utilizaremos la función grepl, que se comporta de manera similar a grep, pero que devolverá un vector lógico en donde los valores TRUE serán para las posiciones en donde se cumpla el patrón y FALSE para las posiciones en donde no. La ventaja de esta función es que podemos combinar los resultados de dos búsquedas con operadores lógicos, en nuestro ejemplo, con el operador Y (&):
posiciones_4_1 <- grepl(x = clientes$nombres, pattern = "Irene")
posiciones_4_2 <- grepl(x = clientes$apellidos, pattern = "Polo")
posiciones_4 <- posiciones_4_1 & posiciones_4_2Y, de nuevo, aplicaremos el filtrado en cualquiera de las dos formas aprendidas. Nótese que con la sintaxis de dplyr es ahora necesario utilizar la función filter en lugar de slice:
clientes[posiciones_4,]
clientes |>
filter(posiciones_4)# A tibble: 1 × 9
nombres apellidos dni nacimiento email categoria continente pais ciudad
<chr> <chr> <dbl> <date> <chr> <chr> <chr> <chr> <chr>
1 Alonso Ir… Polo Mon… 4.50e7 1989-07-04 alpo… A Asia Mald… Malé Ejercicio 5
Premisa: Mostrar los clientes en donde uno de sus nombres sea Irene y que a la vez en alguno de sus nombres exista la letra M.
En Excel
Volvemos a abrir la ventana de Autofiltro personalizado en la columna nombres, pero esta vez llenaremos los campo de la siguiente manera:
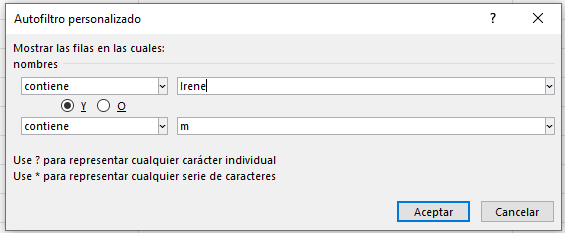
Obtenemos una tabla resultado con 8 registros:

En R
Volveremos a utilizar la función grepl:
posiciones_5_1 <- grepl(x = clientes$nombres, pattern = "Irene")
posiciones_5_2 <- grepl(x = clientes$nombres, pattern = "m", ignore.case = TRUE)
posiciones_5 <- posiciones_5_1 & posiciones_5_2Nótese que hemos aplicado ignore.case = TRUE en una de las búsquedas para indicar que tome en cuenta tanto mayúsculas cuanto minúsculas.
Y, de nuevo, aplicaremos el filtrado en cualquiera de las dos formas aprendidas:
clientes[posiciones_5,]
clientes |>
filter(posiciones_5)# A tibble: 8 × 9
nombres apellidos dni nacimiento email categoria continente pais ciudad
<chr> <chr> <dbl> <date> <chr> <chr> <chr> <chr> <chr>
1 Amancio I… Cañellas… 7.00e7 1996-06-12 amca… C Europa Ando… Andor…
2 Irene Car… Verdugo … 5.30e7 1985-04-10 irve… C África Chad Yamena
3 Roma Irene Girona S… 7.63e7 1991-07-23 rogi… C Europa País… Ámste…
4 Manuelita… Salgado … 3.66e7 1995-04-17 masa… B África Nige… Abuya
5 Irene Rem… Tejada C… 7.02e7 1980-11-14 irte… C Europa Mold… Chese…
6 Martirio … Arranz-M… 4.88e7 1985-02-20 maar… C Europa Finl… Helsi…
7 Montserra… Cózar Pa… 7.23e7 1970-03-21 moco… C África Repú… Bangui
8 Maximilia… Mármol G… 6.37e7 1986-10-02 mama… D Europa Leto… Riga Ejercicio 6
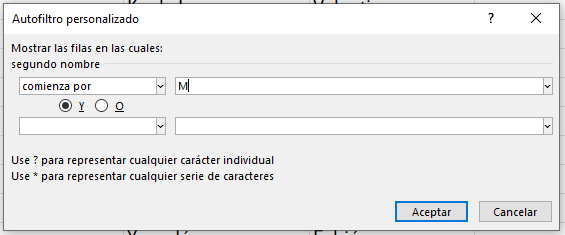
Premisa: Mostrar los clientes en donde su segundo nombre inice con la letra M.
En Excel
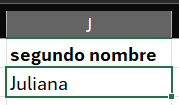
Para este caso, primero tendremos que crear una columna en donde podamos extraer el segundo nombre a partir de las celdas de la columna nombres. Para ello, iremos a la columna a la derecha de ciudad, colocamos un nombre para nuestra nueva columna (segundo nombre) y escribiremos la siguiente fórmula: =EXTRAE(A2, HALLAR(” “,A2)+1,100).

La función EXTRAE requiere como primer argumento la celda input. Su segundo argumento necesita la posición desde donde iniciará la extracción y para ello usaremos la función HALLAR, en donde le solicitaremos que busque un espacio " ". Finalmente, sumaremos 1 a este valor obtenido por HALLAR y completaremos el tercer argumento de EXTRAE que es la posición final (colocamos un número muy alto, 100). Presionamos la tecla Enter y obtendremos lo siguiente:

Como vemos, se ha extraído el segundo nombre (Juliana) y ahora notaremos que al seleccionar nuestra celda, en la esquina inferior derecha que contiene nuestro nuevo valor hay un pequeño cuadradito verde:
Al posicionar el cursor sobre ese cuadradito cambiará su forma (una cruz engrosada) y al dar doble click sobre él, veremos cómo la fórmula se extiende sobre el resto de celdas hacia abajo, generando los valores correspondientes para cada fila.
Ya con esto, podemos volver a aplicar los pasos del Ejercicio 2, pero la letra M:
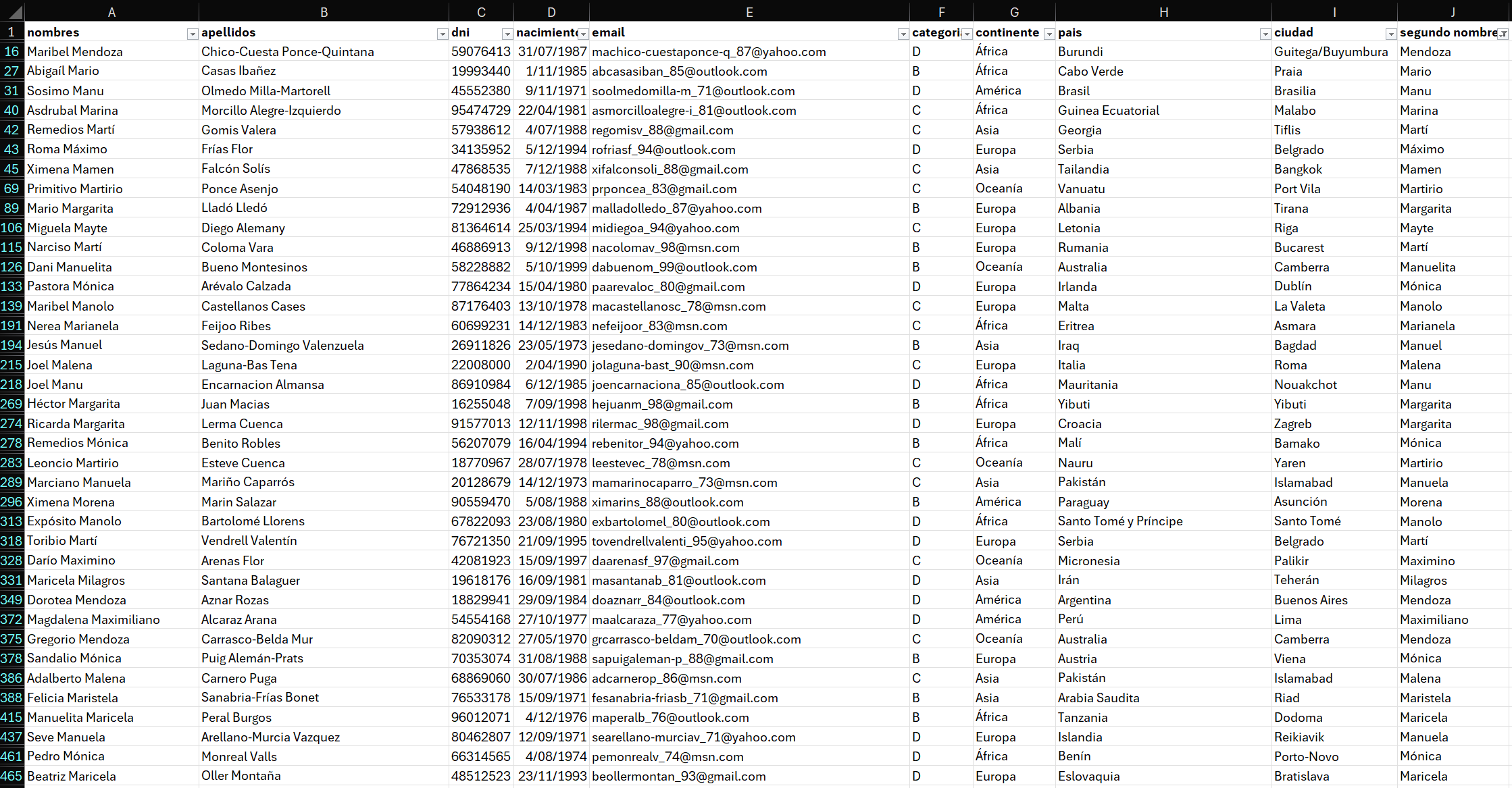
Y de esta manera obtendremos una tabla con 398 registros:
Las fórmulas dependen del idioma
En Excel, el nombre de las fórmulas dependerá del idioma en el que ha sido configurado el paquete de Office. Esto es importante porque si en tu computadora el paquete de Office está en inglés, las funciones HALLAR y EXTRAER serán (re)conocidas como FIND y EXTRACT, respectivamente.
En R
Si bien es posible aplicar la misma estrategia que usamos en Excel de crear una nueva variable y evaluar sobre ella, también podemos realizar lo siguiente:
posiciones_6 <- grep(x = clientes$nombres, pattern = " M")Nótese que dentro del patrón hemos indicado un espacio seguido por la letra M.
Y, de nuevo, aplicaremos el filtrado en cualquiera de las dos formas aprendidas:
clientes[posiciones_6,]
clientes |>
slice(posiciones_6)# A tibble: 398 × 9
nombres apellidos dni nacimiento email categoria continente pais ciudad
<chr> <chr> <dbl> <date> <chr> <chr> <chr> <chr> <chr>
1 Maribel … Chico-Cu… 5.91e7 1987-07-31 mach… D África Buru… Guite…
2 Abigaíl … Casas Ib… 2.00e7 1985-11-01 abca… B África Cabo… Praia
3 Sosimo M… Olmedo M… 4.56e7 1971-11-09 sool… D América Bras… Brasi…
4 Asdrubal… Morcillo… 9.55e7 1981-04-22 asmo… C África Guin… Malabo
5 Remedios… Gomis Va… 5.79e7 1988-07-04 rego… C Asia Geor… Tiflis
6 Roma Máx… Frías Fl… 3.41e7 1994-12-05 rofr… D Europa Serb… Belgr…
7 Ximena M… Falcón S… 4.79e7 1988-12-07 xifa… C Asia Tail… Bangk…
8 Primitiv… Ponce As… 5.40e7 1983-03-14 prpo… C Oceanía Vanu… Port …
9 Mario Ma… Lladó Ll… 7.29e7 1987-04-04 mall… B Europa Alba… Tirana
10 Miguela … Diego Al… 8.14e7 1994-03-25 midi… C Europa Leto… Riga
# ℹ 388 more rows